GraphQL, Hasura, PostgreSQL, Apollo
本节介绍 GraphQL、Hasura、PostgreSQL(关系型数据库)、Apollo,这是目前网站主要拉取数据的方案。
四个部分大致是如下图构成数据查询流程。即编写查询相关的 GraphQL 语句,Apollo 会生成相应的 TS 代码,经编译后运行在 Node.js 上,使用 GraphQL 的形式与 Hasura 进行交互,由 Hasura 访问 PostgreSQL 数据库存取数据。

接下来,将逐步讲解以下概念:
- 什么是“关系型数据库”?SQL 又是什么?
- 从 SQL 到 GraphQL
- 使用 Hasura+PostgreSQL 来管理数据
- 使用 Apollo 编写查、增、删、改
相关链接:
关系型数据库与 SQL
数据库,顾名思义是存储数据的。我们常用实体-联系的方式来对数据进行抽象,其中实体是客观存在并可相互区分的事物,而联系指的是不同(类)实体之间的关系。关系型数据库指的是使用关系模型来存储数据。

不同实体间的联系一般分为“一对一”、“一对多”、“多对多”三种,可以借助三个例子理解:
- 一对一:一个班有一个班主任,一个班主任负责一个班
- 一对多:一个作者可以写多篇文章
- 多对多:一个用户可以关注多个用户,同时被多个用户关注
而关系模型则是使用一张表来存储数据,比如
| 用户信息 | ||
|---|---|---|
| id | 用户名 | 性别 |
| 1 | 张三 | 男 |
| 2 | 古河渚 | 女 |
| 3 | 秀吉 | 秀吉 |
表中每列是一个属性,每行是一个实体的数据(也称元组)。总应有至少一个属性可以唯一标识元组,称为候选码,选其中一个作为主码。部分属性可能是其他关系表中的主码,称为外码。我们会在接下来的例子中看到这些“码”。
SQL(Structured Query Language,结构化查询语言)是用来对数据进行查询、添加、删除、更改的语言,这里只简单介绍查询功能。假定我们有三个表分别存学生、课程、学生-课程,我们可以使用如下的 SQL 语句进行查询:
查询全体学生的学号和姓名
SELECT stu_no, stu_name
FROM Student;
查选修C1课程的学生的学号和成绩,并按分数降序排列
SELECT stu_no, grade
FROM StudentCourse
WHERE course_no='C1'
ORDER BY grade DESC;
更多有关 SQL 的内容不是培训重点,建议感兴趣的同学自行学习。
GraphQL
SQL 较为古老,对于数据量大且关系复杂的查询不够直观,GraphQL 则是一个更为直观的查询语言。
在 JS / json 中,我们使用类似的结构来表示对象
[
{
"username": "Zhang San",
"gender": "male"
},
{
"username": "Nagisa",
"gender": "female"
}
]
我们可以使用极为相似的 GraphQL 语句来查询
query {
user {
username
}
}
得到相应的 json 结果
{
"data": {
"user": [
{
"username": "Zhang San"
},
{
"username": "Nagisa"
}
]
}
}
一个更为复杂的例子
query GetArticleFeeds(
$limit: Int = 2
$cursor: timestamptz!
$authorId: String
$title: String
$alias: String
$abstract: String
$content: String
) {
article_public(
limit: $limit
where: {
_and: [
{ created_at: { _lte: $cursor } }
{ authorId: { _eq: $authorId } }
{ title: { _ilike: $title } }
{ alias: { _ilike: $alias } }
{ abstract: { _ilike: $abstract } }
{ content: { _ilike: $content } }
]
}
order_by: { created_at: desc }
) {
id
alias
title
abstract
views
created_at
author {
username
}
article_tags {
tag {
tag_name
}
}
article_likers_aggregate {
aggregate {
count(distinct: true)
}
}
}
}
这是正在开发的 Weekly 用来获取文章信息的语句(可能会有更改)。最前面的$加字符串表示查询语句中使用的变量,后面加感叹号表示该项必须存在。这些变量在下方的where中使用,用来限制查询结果。最后面的花括号中包含的内容是要得到的数据,其中author、article_tags和articl_likers_aggregate是利用外码获取对应的作者信息、标签信息、喜欢文章的用户的统计信息。
用于更改(增删)的语句则使用mutation关键字
mutation InsertArticle(
$abstract: String = ""
$alias: String!
$content: String!
$authorId: String!
$title: String!
$tags: [article_tag_insert_input!]! = []
) {
insert_article_one(
object: {
abstract: $abstract
alias: $alias
content: $content
authorId: $authorId
title: $title
article_tags: {
data: $tags
on_conflict: { constraint: article_tag_pkey, update_columns: tag_id }
}
}
on_conflict: { constraint: article_alias_key, update_columns: [] }
) {
id
}
}
这段语句将基于给定的变量,创建一篇文章,并返回文章的 id。
Hasura 和 PostgreSQL
前面讲的 GraphQL 看上去很美化,但要自行实现相应的 API 不是一件容易的事,因此我们选用 Hasura GraphQL Engine。
Hasura 是开源的 GraphQL 引擎,默认使用 PostgreSQL 数据库存储数据,可以使用其提供的 console 页面创建数据表、增删改数据、设置操作权限、测试 GraphQL 语句。下面将从安装开始“浏览”基本使用。
安装
参照官方文档,我们使用 docker 进行安装。首先修改官方提供的docker-compose.yaml
version: "3.6"
services:
postgres:
image: postgres:latest
container_name: postgres
restart: always
volumes:
- ~/data/postgres:/var/lib/postgresql/data
ports:
- "5432:5432"
environment:
POSTGRES_PASSWORD: postgrespassword
graphql-engine:
image: hasura/graphql-engine:latest
container_name: hasura
ports:
- "23333:8080"
depends_on:
- "postgres"
restart: always
environment:
HASURA_GRAPHQL_DATABASE_URL: postgres://postgres:postgrespassword@postgres:5432/postgres
HASURA_GRAPHQL_ENABLE_CONSOLE: "true" # set to "false" to disable console
HASURA_GRAPHQL_ENABLED_LOG_TYPES: startup, http-log, webhook-log, websocket-log, query-log
## uncomment next line to set an admin secret
# HASURA_GRAPHQL_ADMIN_SECRET: myadminsecretkey
注意其中需要修改的几处地方:
- 容器端口绑定宿主机端口是否会冲突
- PostgreSQL 的密码是否需要设置
- Hasura 的密码是否需要设置(默认不设置)
在修改好后的docker-compose.yaml所在路径使用如下命令拉取镜像并启动容器
docker-compose up -d
启动后,我们使用docker ps -a可以查看容器状态(类似下方所示)
CONTAINER ID IMAGE ... CREATED STATUS PORTS ...
097f58433a2b hasura/graphql-engine ... 1m ago Up 1m 0.0.0.0:23333->8080/tcp ...
b0b1aac0508d postgres ... 1m ago Up 1m 0.0.0.0:5432->5432/tcp ...
现在访问localhost:23333/console可以进入 Hasura 的控制界面
Hasura 提供许多功能,我们主要使用GRAPHIQL和DATA两个页面的功能
创建与管理数据
在DATA页面可以创建“关系表”,比如创建一个user:
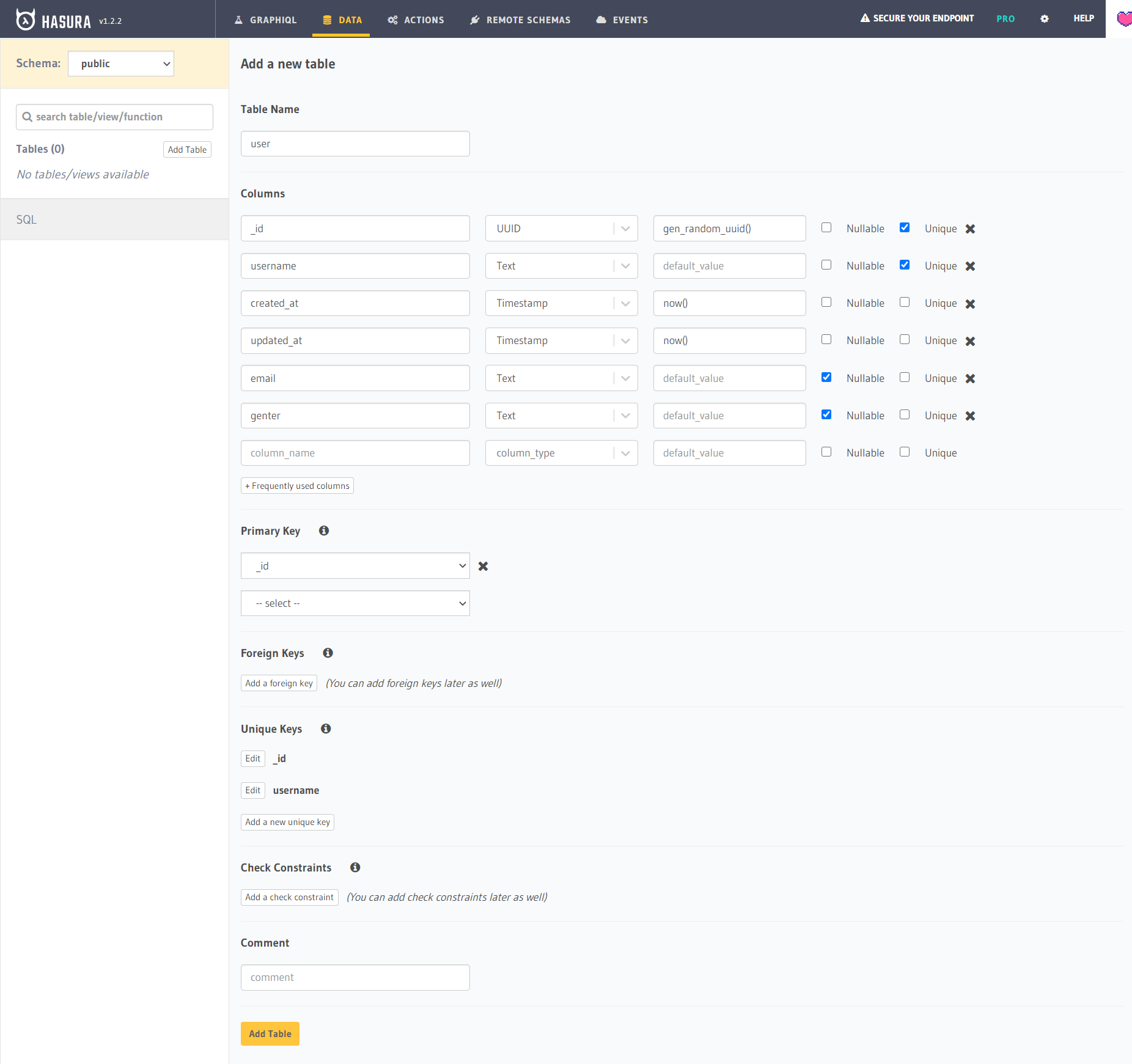
这里填入了 6 个属性,其中_id为主码,使用数据库的 uuid 生成器得到。username、email、gender皆为字符串,其中username也是不可重复的(我们称为候选码),而email和gender则是可以为空的普通属性。created_at和updated_at则是使用+ Frequently used columns添加的,分别会根据创建和更改时的时间自动添加。
我们再来创建一个article表,加入作者的_id作为外码:
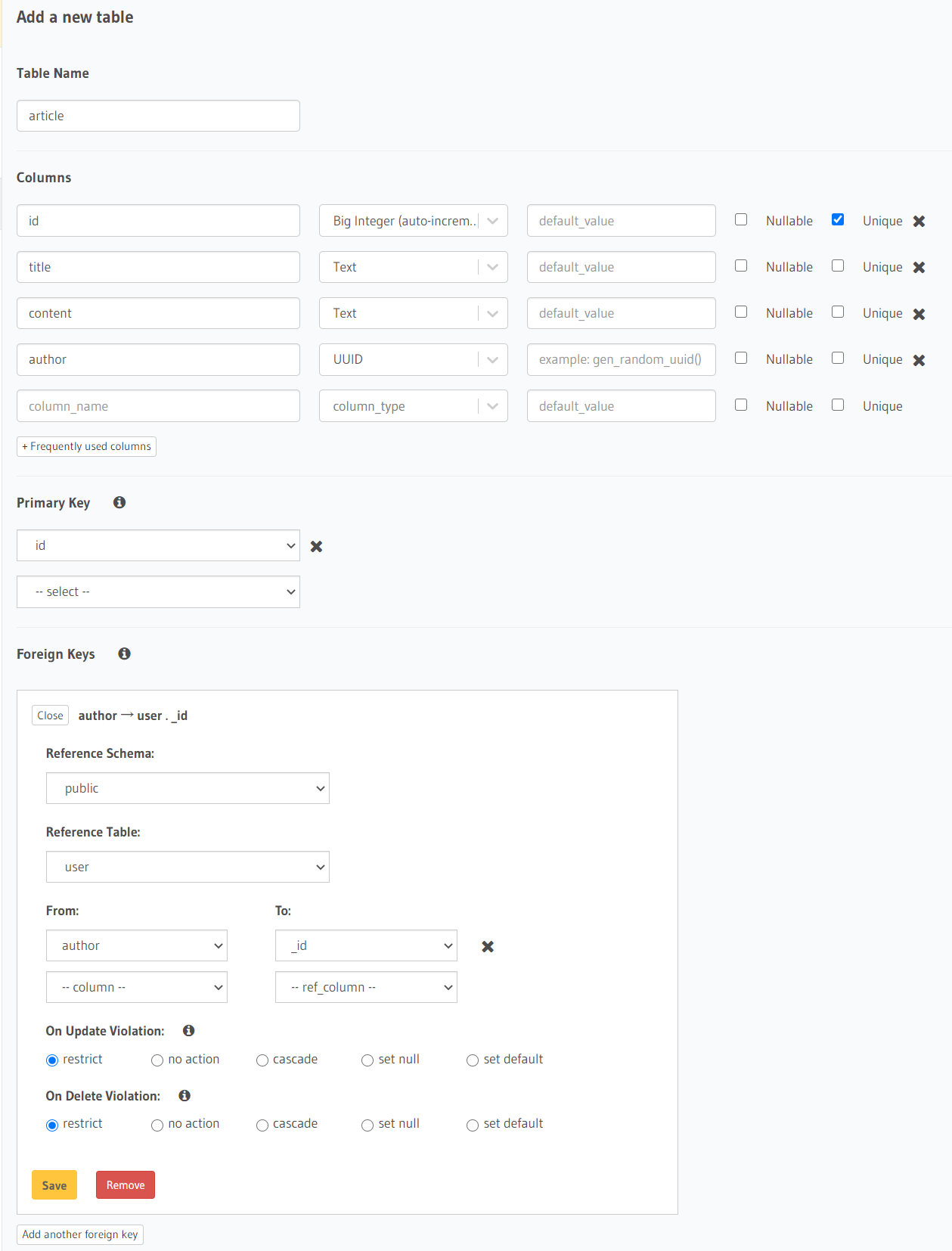
这里将author的值设为 uuid 类型,并与user._id严格一致。我们点开article的Relationships可以看到推荐的关系设置:
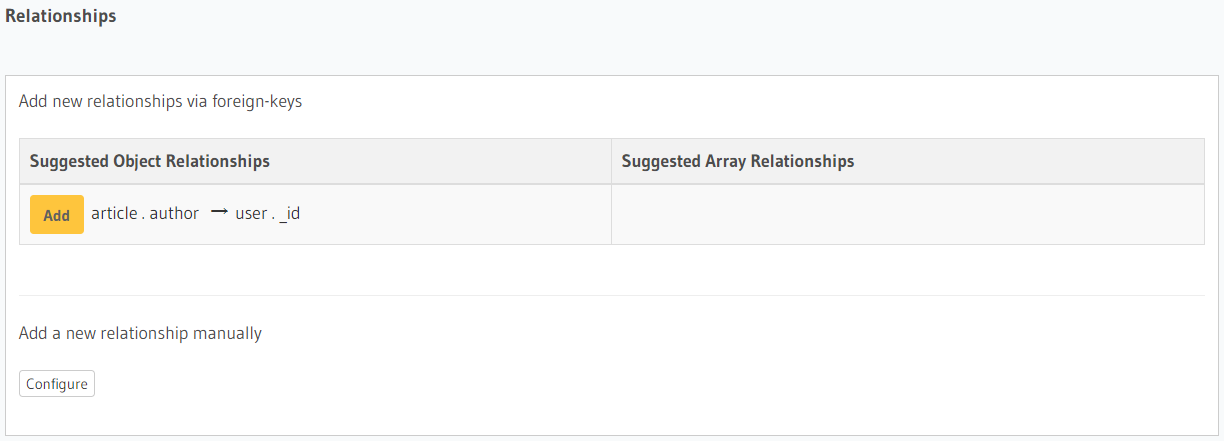
这里推荐添加Object relationships,而在user的Relationships可以看到推荐Array relationships。点击添加便是告诉 Hasura 这两个表之间是一对多的关系,即一个user可以有多篇article。我们可以在GRAPHIQL页面试着写一下查询语句:
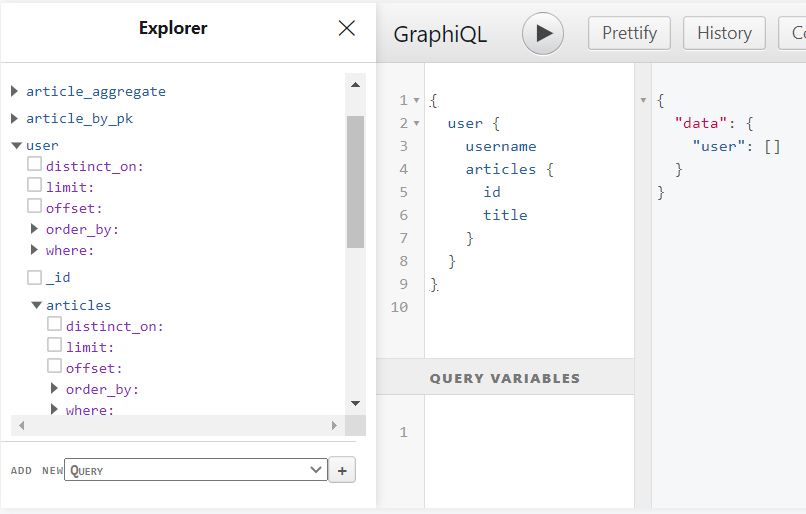
一般限制条件不太复杂的查询或者更改操作,都可以使用最左侧的 Explorer 勾选需要的部分,由 Hasura 生成中间的语句,点击“执行”按钮可以在右边看到结果。这里因为还没有添加数据,所以是空的。
对于更为复杂的关系,比如“喜欢一篇文章”这种多对多关系,我们需要再创建一个表,只有article_id和user_id两个属性,一起作为主码,又同时是外码。当表中存在这样的数据时,就表明某用户喜欢某篇文章。
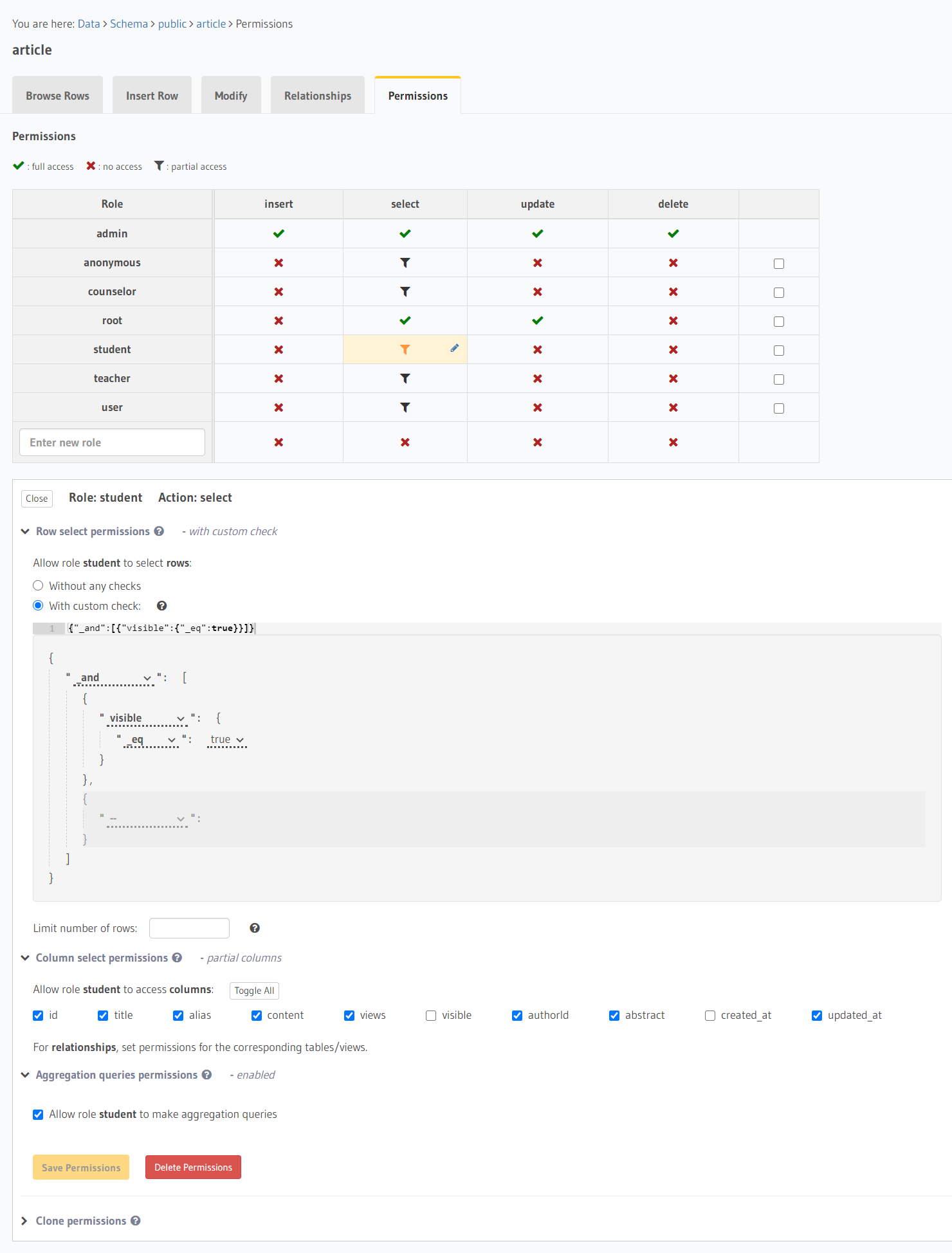
最后我们再看一下“权限控制”。在表的Permissions页面可以设置不同身份用户的插入、查询、更改与删除权限。目前 Hasura 提供的权限设置自由度较小,如果要设置非常复杂的权限,需要通过添加数据表的view再给其设置权限等方法来实现。具体细节可以参看Multiple column + row permissions for the same role
Apollo
我们这里说的 Apollo 主要指的是 Apollo Client (React),实现了拉取并管理数据的功能。Apollo 本身会根据配置好的服务端的数据,将本地写好的GraphQL语句编译为typescript接口。
目前的前端项目中,我们在src/api文件夹下编写*.graphql文件,即填写在 Hasura 中测试过得到需要结果的query或mutation语句。之后使用 Apollo 的codegen编译为相应的接口,供前端页面拉取数据使用。
我们使用 Apollo 提供的useQuery和useMutation来进行数据的获取和更改。参考官方文档使用useQuery:
const GET_DOG_PHOTO = gql`
query Dog($breed: String!) {
dog(breed: $breed) {
id
displayImage
}
}
`;
function DogPhoto({ breed }) {
const { loading, error, data } = useQuery(GET_DOG_PHOTO, {
variables: { breed },
});
if (loading) return null;
if (error) return `Error! ${error}`;
return (
<img src={data.dog.displayImage} style={{ height: 100, width: 100 }} />
);
}
观察到有一个变量,存的是 GraphQL 的语句,并将这个变量传入useQuery,返回的是data、loading和error三项。顾名思义,是返回的数据、加载状态与是否错误。迁移到typescript是类似这样的:
query GetUser($_id: String!) {
user(where: { _id: { _eq: $_id } }) {
_id
id
name
username
department
class
phone
email
}
}
import { GetUser as GET_USER } from "../api/user.graphql";
import { GetUser, GetUserVariables } from "../api/types";
const { data, loading, error } = useQuery<GetUser, GetUserVariables>(GET_USER, {
variables: { _id: userData?._id! },
});
这里从user.graphql中导入了GetUser的片段并起别名叫GET_USER,并从 Apollo 生成的接口中导入GetUser和GetUserVariables,即告诉useQuery要使用GET_USER的形式发送请求。之后每次渲染useQuery所在的组件时,便会执行这个请求拉取用户信息。
而mutation所用的useMutation则是会创建一个函数,显式调用以进行更改的操作。
mutation UpdateUser(
$_id: String!
$id: bigint!
$username: String
$phone: String
$name: String
$department: String
$class: String
$email: String
) {
update_user(
where: { _id: { _eq: $_id } }
_set: {
id: $id
username: $username
phone: $phone
name: $name
department: $department
class: $class
email: $email
}
) {
affected_rows
}
}
import { UpdateUser as UPDATE_USER } from "../api/user.graphql";
import { UpdateUser, UpdateUserVariables } from "../api/types";
const [
updateUser,
{ data: updateData, loading: updating, error: updateError },
] = useMutation<UpdateUser, UpdateUserVariables>(UPDATE_USER);
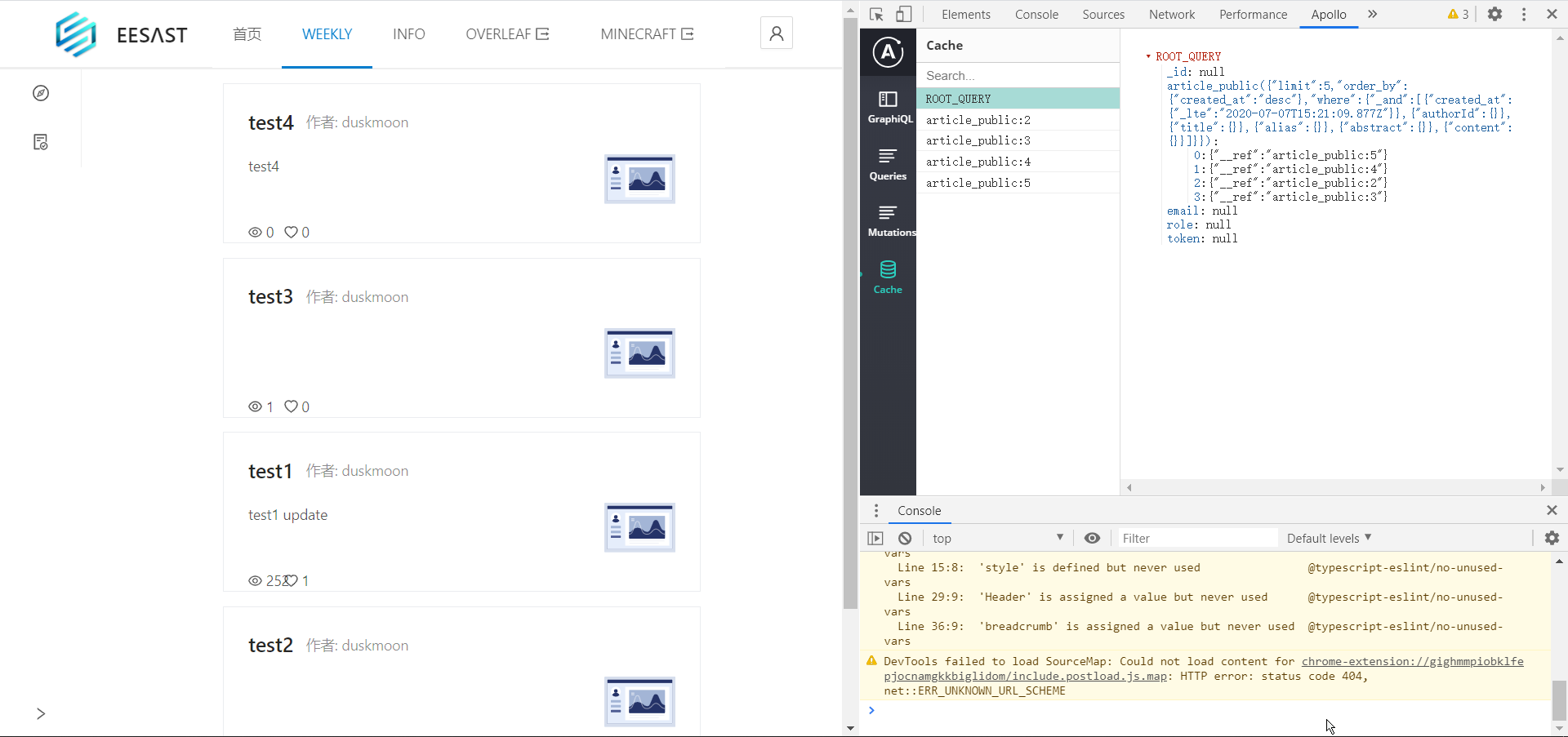
下面我们来看查询和更改的例子。我们在数据库里存了很多文章,现在我们要获取并用一个列表展示它们。当用户点击文章时会跳转到相应页面进行阅读,同时更改数据库中该文章的view属性(加 1)。
const { data, loading, error } = useQuery<
GetArticleFeeds,
GetArticleFeedsVariables
>(GET_ARTICLE_FEEDS, {
variables: { limit: 5, cursor: cursor },
});
useEffect(() => {
if (data) {
setArticles(
data.article_public.map((article) => {
return {
title: article.title!,
alias: article.alias!,
abstract: article.abstract!,
author: article.author?.username!,
likes: article.article_likers_aggregate.aggregate?.count!,
views: article.views!,
tags: article.article_tags.map((t) => t.tag.tag_name),
};
})
);
}
}, [data]);
return (
<Row>
<Col span={4}></Col>
<Col span={16}>
<List
dataSource={articles}
renderItem={(item) => {
return (
<Link to={`/weekly/explore/${item.alias}`}>
<ArticleFeedCard article={item} />
</Link>
);
}}
></List>
</Col>
<Col span={4}></Col>
</Row>
);
这里使用useQuery,基于cursor(用来确定获取文章的时间戳,初始化为当前时间)拉取 5 篇文章,并使用map变为<ArticleFeedCard />组件接收的参数。
const [
viewArticle,
{ data: articleData, loading: articleLoading, error: articleError },
] = useMutation<ViewArticle, ViewArticleVariables>(VIEW_ARTICLE);
useEffect(() => {
viewArticle({
variables: { alias: alias },
});
}, [alias, viewArticle]);
useEffect(() => {
if (articleData && !articleError && articleData.update_article_public) {
setArticle(articleData?.update_article_public?.returning[0]);
setContentHtml(
md2wx.renderHtml(
articleData?.update_article_public?.returning[0].content!
)
);
}
}, [articleData, articleError]);
在文章的阅读页面,则是使用mutation同时修改view并获取文章的内容,再存储到组件的状态中,以备其他功能需要。
Apollo 的简短介绍到这里就结束了,对于更深内容感兴趣的同学可以自行查阅其文档学习。
写在最后
GraphQL 整体上是比较新的一种技术,直观是其优势。同时,也因为较新,轮子会相对少一些,有中文文档的轮子就更少了。此外,部分轮子还在迅速的演进,会有较多的BREAKING CHANGE,有可能代码刚写完,不小心更新一下依赖就挂掉了(笑)。为了减少这种更新带来的麻烦,我们一般会使用“机器人”来尝试更新依赖,即持续集成。具体内容将在下一节中讲解。