Introduction
本文档为清华电子系学生科协 2020 年暑期培训仓库中各部分内容介绍及相关依赖的简要安装说明。
培训所用的文档、教学用 PPT 及相关仓库与依赖链接基本上可以在仓库中找到。
EESAST Training 2020 由 EESAST 采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。 多数内容将以 CC-BY-SA 4.0 进行许可,部分培训内容的作者可能会有特殊许可,若有需要还请注意。

培训内容主要分为三个大部分:
- 基础工具 Git, Docker
- 队式开发技术栈
- 网站开发技术栈
具体内容还请参阅各章说明
Git
Git 是一个分布式版本管理系统,虽然设计上可能存在一些问题,但不妨碍其成为如今使用最广的地位。软件部的开发采取 Git 进行版本管理,也推荐大家将 Git 应用到各种需要版本管理的地方。
参考链接
web
这一章将基于 EESAST 目前网站方面使用的技术进行培训,内容主要为以下几个部分:
- Html, CSS, JavaScript/TypeScript 基础
- Node.js 与包管理
- React + antd
- Restful API 与 Express
- GraphQL + Hasura + Apollo
- 数据库 MongoDB 和 PostgreSQL
- Web测试 Mocha + Chai
- CI/CD
具体内容安排请参照各小节说明
需要用到的工具及相关链接如下:
- Visual Studio Code
- Node.js
- Yarn
- React
- Ant Design
- Express
- GraphQL
- Hasura
- Apollo
- MongoDB
- PostgreSQL
- Mocha
- Chai
- GitHub Actions
HTML&CSS 入门
这里介绍的知识非常基础,因为网站组的同学们在后面写网站的时候很少直接写 HTML&CSS(尤其是 HTML),这里讲只是为了让大家简单了解下网页的机制
本文档参考MDN完成,希望深入学习的同学可以参考
HTML
参考:https://developer.mozilla.org/zh-CN/docs/Web/HTML
基础
HTML (Hyper Text Markup Language) 不是一门编程语言,而是一种用来告知浏览器如何组织页面的标记语言。HTML 可复杂、可简单,一切取决于开发者。它由一系列的元素(elements)组成,这些元素可以用来包围不同部分的内容,使其以某种方式呈现或者工作。 一对标签( tags)可以为一段文字或者一张图片添加超链接,将文字设置为斜体,改变字号,等等。
最简单的一个内容是这样的
欢迎大家加入科协
<p>欢迎大家加入科协</p>
这是一个段落(p)元素,一个 html 元素的组成分为
- 开始标签(Opening tag):包含元素的名称,被左、右角括号所包围。表示元素从这里开始或者开始起作用
- 结束标签(Closing tag):与开始标签相似,只是其在元素名之前包含了一个斜杠。这表示着元素的结尾 —— 在本例中即段落在此结束。初学者常常会犯忘记包含结束标签的错误,这可能会产生一些奇怪的结果。
- 内容(Content):元素的内容,本例中就是所输入的文本本身。
- 元素(Element):开始标签、结束标签与内容相结合,便是一个完整的元素。
HTML 元素可以进行嵌套,比如
欢迎大家加入科协
<p><em>欢迎</em>大家加入<strong>科协</strong></p>
块级元素和内联元素
块级元素在页面中以块的形式展现 —— 相对于其前面的内容它会出现在新的一行,其后的内容也会被挤到下一行展现,例如上面的<p>
内联元素通常出现在块级元素中并环绕文档内容的一小部分,而不是一整个段落或者一组内容。内联元素不会导致文本换行:它通常出现在一堆文字之间例如超链接元素<a>或者强调元素<em>和<strong>。
空元素
不是所有元素都拥有开始标签,内容,结束标签,一些元素只有一个标签,通常用来在此元素所在位置插入/嵌入一些东西,比如<img>
属性
使用属性来给元素设定额外信息,属性的基本写法为
<p class="foobar">EESAST</p>
用空格与元素名或前一个属性隔开,属性名="值"(单引号双引号都可)
比较典型的例子就是元素<a>,用来创建链接
<a href="https://eesast.com" title="科协官网">EESAST</a>
一个 HTML 文件的结构
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>我的测试站点</title>
</head>
<body>
<p>这是我的页面</p>
</body>
</html>
<!DOCTYPE html>: 声明文档类型<html></html>:<html>元素。这个元素包裹了整个完整的页面,是一个根元素。<head></head>:<head>元素.<meta charset="utf-8">: 元数据,在这里是设置文档使用 utf-8 字符集编码,也可以像<meta name="author" content="Chris Mills">这样用 name 和 content 来设置其他信息,当然在不同的应用场景可以设置很多不同的元数据<title></title>: 设置页面标题<body></body>:<body>元素, 包含了你访问页面时所有显示在页面上的内容
在 HTML 中应用 CSS 和 JavaScript
对于 CSS,需要加入一个<link>元素,rel="stylesheet"表明这是文档的样式表,而 href 包含了样式表文件的路径,这个元素一般放在<head>里
<link rel="stylesheet" href="my-css-file.css" />
对于 js 脚本,加入<script>元素,src 为脚本的路径。<script>部分没必要非要放在文档头部,实际上,把它放在文档的尾部</body>标签之前是一个更好的选择,这样可以确保在加载脚本之前浏览器已经解析了 HTML 内容
<script src="my-js-file.js"></script>
这里 script 元素没有内容,但他不是一个空元素,你也可以直接把脚本写在元素里
HTML 的基本布局
<header>:页眉。<nav>:导航栏。<main>:主内容。主内容中还可以有各种子内容区段,可用<article>、<section>和<div>等元素表示。<aside>:侧边栏,经常嵌套在<main>中。<footer>:页脚。
关于完整的 html 元素和属性,可以参考这里
CSS
参考:https://developer.mozilla.org/zh-CN/docs/Web/CSS
基础
CSS 是一门基于规则的语言,他的基础结构为:由一个选择器开头,后接一对大括号,在大括号内部定义一个或多个形式为 属性(property):值(value); 的声明(declarations)。每个声明都指定了我们所选择元素的一个属性,之后跟一个我们想赋给这个属性的值。这里可以查看所有属性。
h1 {
color: red;
font-size: 5em;
}
p {
color: black;
}
元素选择器
使用元素选择器来直接匹配一种 html 元素
p {
color: green;
}
不同的选择器可以用,隔开来使用多个选择器
p, li { color: green; }
这种直接指定元素类型的写法只能同时应用于所有同类元素,在实际使用的时候是十分不方便的,因此我们还可以使用类名来进一步指定作用的对象。前面说到 HTML 中的元素可以添加属性,这里的类名选择器就对应标签中的class属性,比如
<ul>
<li>项目一</li>
<li class="special">项目二</li>
<li>项目 <em>三</em></li>
</ul>
.special {
color: orange;
font-weight: bold;
}
这里指定了属于 special 类的元素进行设置,在在选择器的开头加.即为指定类,当然可以同时指定元素和类
li.special,
span.special {
color: orange;
font-weight: bold;
}
此外,我们还可以根据元素的位置来进行选择,在选择器中使用空格来表示包含(嵌套)关系,用+来表示相邻关系,例如
li em {
color: rebeccapurple;
}
表示选择嵌套在<li>内部的<em>
h1 + p {
font-size: 200%;
}
表示选择跟在<h1>后面的<p>
可以尝试下解读这个选择器
body h1 + p .special {
color: yellow;
background-color: black;
padding: 5px;
}
盒模型
参考:https://developer.mozilla.org/zh-CN/docs/Learn/CSS/Building_blocks/The_box_model
在 CSS 中,所有的元素都被一个个的“盒子(box)”包围着,理解这些“盒子”的基本原理,可以帮助我们使用 CSS 实现准确布局、处理元素排列。
CSS 中组成一个块级盒子需要:
- Content box: 这个区域是用来显示内容,大小可以通过设置
width和height. - Padding box: 包围在内容区域外部的空白区域; 大小通过
padding相关属性设置。 - Border box: 边框盒包裹内容和内边距。大小通过
border相关属性设置。 - Margin box: 这是最外面的区域,是盒子和其他元素之间的空白区域。大小通过
margin相关属性设置。
如下图:
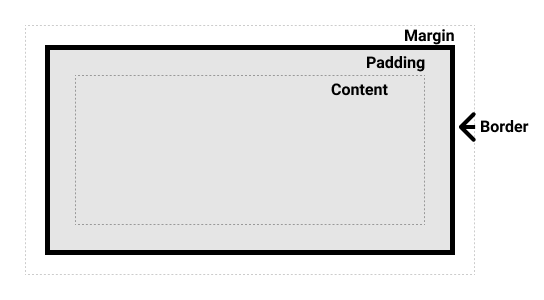
在标准模型中,如果你给盒设置 width 和 height,实际设置的是 content box。 padding 和 border 再加上设置的宽高一起决定整个盒子的大小
.box {
width: 350px;
height: 150px;
margin: 25px;
padding: 25px;
border: 5px solid black;
}
可以尝试计算一下这个盒子的大小
JavaScript&TypeScript
JavaScript
参考:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/A_re-introduction_to_JavaScript
更详细的JavaScript学习资料:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript
什么是JavaScript
JavaScript 是一门跨平台、面向对象的脚本语言,它能使网页可交互(尽管我们这里不会介绍这部分内容)。 JavaScript 堪称世界上被人误解最深的编程语言,虽然常被嘲为“玩具语言”,但在它看似简洁的外衣下,还隐藏着强大的语言特性。 JavaScript 目前广泛应用于众多知名应用中,对于网页和移动开发者来说,深入理解 JavaScript 就尤为必要。
与大多数编程语言不同,JavaScript 没有输入或输出的概念。它是一个在宿主环境(host environment)下运行的脚本语言,任何与外界沟通的机制都是由宿主环境提供的。浏览器是最常见的宿主环境,但在非常多的其他程序中也包含 JavaScript 解释器,如 Adobe Acrobat、Adobe Photoshop、SVG 图像、Yahoo! 的 Widget 引擎,Node.js之类的服务器端环境。
我们有时候也会看到ECMAScript或者ES6之类的称呼,ECMA是JavaScript 的标准化组织,ECMAScript是针对 JavaScript 语言制定的标准,之所以不叫 JavaScript,是因为Java和JavaScript的商标都被注册了。因此ECMAScript 和 JavaScript 的关系是,前者是后者的规格,后者是前者的一种实现(另外的 ECMAScript 方言还有 JScript 和 ActionScript)
JavaScript基础语法
JavaScript 是一种多范式的动态语言,它包含类型、运算符、标准内置( built-in)对象和方法。在基本语法方面,JavaScript有很多和C/C++相似的地方。JavaScript同样支持函数式编程——因为它们也是对象,函数也可以被保存在变量中,并且像其他对象一样被传递。
数据类型
JavaScript 中的类型如下
-
Number(数字)- 3/2=1.5
- 特殊的值
NaN(Not a Number 的缩写),如果把NaN作为参数进行任何数学运算,结果也会是NaN。NaN如果通过==、!=、===、以及!==与其他任何值比较都将不相等 -- 包括与其他 NAN值进行比较。必须使用Number.isNaN()或isNaN()函数 - 内置对象
Math支持一些高级的计算;
-
String(字符串)-
JavaScript 中的字符串是一串Unicode 字符序列
-
'和"皆可 -
可以使用内置函数
parseInt()和parseFloat()来将字符串转为number -
可以在字符串字面值上使用字符串对象的所有方法——JavaScript会自动将字符串字面值转换为一个临时字符串对象,调用该方法,然后废弃掉那个临时的字符串对象,比如
'eesast'.length -
在ES2015中,引入了模板字符串,使用反引号 (` `) 来代替普通字符串中的用双引号和单引号,我们对其最常见的使用就是使用占位符
${expression}来在其中插入表达式,例如let name = "Bob", time = "today"; `Hello ${name}, how are you ${time}?` let a = 5; let b = 10; console.log(`Fifteen is ${a + b} and not ${2 * a + b}.`);
-
-
Boolean(布尔) -
Symbol(符号)(ES2015 新增) -
Object(对象)
-
null(空) -
undefined(未定义)
可以看到函数和数组也属于对象
注释
JavaScript 注释的语法和 C++ 或许多其他语言类似
// 单行注释
/* 这是一个更长的,
多行注释
*/
变量
JavaScript有三种声明变量的方式。
如果声明了一个变量却没有对其赋值,那么这个变量的类型就是 undefined
const很明显是一个常量,他是只读的,而let与var的主要区别在于,let的作用域是块作用域,而var的作用域是全局或者函数作用域(const也是块作用域),并且let没有变量提升
最简单的例子如下
{
let a = 10;
var b = 1;
}
a // ReferenceError: a is not defined.
b // 1
有关变量提升,指的是
// var 的情况
console.log(foo); // 输出undefined
var foo = 2;
// let 的情况
console.log(bar); // 报错ReferenceError
let bar = 2;
他们的详细区别可见此处
运算符
这里只介绍与C++不同的部分
-
求幂:
x**2 -
全等和不全等:
x===yx!==y比较两个操作数是否相等且类型相同 -
一元的正:即
+,如果操作数在之前不是number,试图将其转换为number -
字符串运算:
+可以直接连接两个字符串,并同时会尝试将另一个操作数转换为string -
解构赋值:将属性/值从对象/数组中取出,赋值给其他变量,例如
var a, b, rest; [a, b, ...rest] = [10, 20, 30, 40, 50]; console.log(a); // 10 console.log(b); // 20 console.log(rest); // [30, 40, 50] var o = {p: 42, q: true}; var {p, q} = o;
控制结构
JavaScript 的控制结构与其他类 C 语言类似,在此进行一下罗列
var name = "kittens";
if (name == "puppies") {
name += "!";
} else if (name == "kittens") {
name += "!!";
} else {
name = "!" + name;
}
name == "kittens!!"; // true
//--------------------------------------
while (true) {
// 一个无限循环!
}
var input;
do {
input = get_input();
} while (inputIsNotValid(input))
//---------------------------------------
for (var i = 0; i < 5; i++) {
// 将会执行五次
}
//---------------------------------------
switch(action) {
case 'draw':
drawIt();
break;
case 'eat':
eatIt();
break;
default:
doNothing();
}
JavaScript 也还包括其他两种重要的 for 循环: for...of
for (let value of array) {
// do something with value
}
和 for...in :
for (let property in object) {
// do something with object property
}
for ... in是为遍历对象属性而构建的,不建议与数组一起使用
对象
JavaScript 中的对象,Object,可以简单理解成“名称-值”对,与我们知道的Python 中的字典(Dictionary)、C/C++ 中的散列表(Hash table)比较相似
有两种简单方法可以创建一个空对象:
var obj = new Object();
和:
var obj = {};
这两种方法在语义上是相同的。第二种更方便的方法叫作“对象字面量(object literal)”法。这种也是 JSON 格式的核心语法,一般我们优先选择第二种方法。
有关对象的访问和成员设置
person.age = 45
person['name']['last'] = 'Cratchit'
和大家刚学过的C++类似,这里的对象也有this来指向了当前代码运行时的对象
有关OOP的细节在这里不再介绍,其概念与C++有一些相似性,如果想复习一下OOP并且了解Js中的对象可以参考这里
函数
最简单的函数定义十分简单
function add(x, y) {
var total = x + y;
return total;
}
如果调用函数时没有提供足够的参数,缺少的参数会被 undefined 替代,而事实上你传入的参数在一个名为 arguments 的函数内部对象中,可以像数组一样来访问它,所以你传入了过多的参数也是可以的
function add() {
var sum = 0;
for (var i = 0, j = arguments.length; i < j; i++) {
sum += arguments[i];
}
return sum;
}
add(2, 3, 4, 5); // 14
arguments写起来又丑又长,我们可以用剩余参数来实现相似的功能。剩余参数操作符在函数中以:...variable 的形式被使用,它将包含在调用函数时使用的未捕获整个参数列表到这个变量中,例如
function avg(first, ...args) {
var sum = first;
for (let value of args) {
sum += value;
}
return sum / args.length;
}
avg(2, 3, 4, 5); // 3.5
和剩余参数操作符长得一样的一个语法是展开语法,展开语法(Spread syntax), 可以在函数调用/数组构造时, 将数组表达式或者string在语法层面展开;还可以在构造字面量对象时, 将对象表达式按key-value的方式展开。例如
let a = [1,2,3]; let b = {1:"1",2:"2"} let c = [...a, 4]; //[1, 2, 3, 4] let d ={...b,3:"3"}; //{1: "1", 2: "2", 3: "3"}可以看到这种语法在利用已有的数组/对象构造新的数组/对象时十分方便
JavaScript 也允许在一个函数内部定义函数,它们可以访问父函数作用域中的变量
function parentFunc() {
var a = 1;
function nestedFunc() {
var b = 4; // parentFunc 无法访问 b
return a + b;
}
return nestedFunc(); // 5
}
JavaScript 允许创建匿名函数,可以通过函数表达式来实现,函数表达式也可以被赋值给一个变量,例如
//直接调用
(function(x, y){
return x + y;
})(1,2);
//3
//作为参数传递
setTimeout(function(){console.log('111');},1000);
//赋值给变量
const add = function(x, y){
return x + y;
}
add(1,2);
//3
而除了函数表达式之外,我们还有一种更加简洁的方式来创建函数--箭头函数
引入箭头函数有两个方面的作用:更简短的函数并且不绑定this
箭头函数的基本语法为
(param1, param2, …, paramN) => { statements }
(param1, param2, …, paramN) => expression
//相当于:(param1, param2, …, paramN) =>{ return expression; }
// 当只有一个参数时,圆括号是可选的:
(singleParam) => { statements }
singleParam => { statements }
// 没有参数的函数应该写成一对圆括号。
() => { statements }
在使用匿名函数的地方箭头函数是十分常见的,箭头函数没有单独的this,不绑定arguments,不能用作构造函数,不太适合作为方法
异步
异步基本概念
通常来说,程序都是顺序执行,同一时刻只会发生一件事。如果一个函数依赖于另一个函数的结果,它只能等待那个函数结束才能继续执行。这是令人沮丧的体验,没有充分利用计算机的计算能力 — 尤其是在计算机普遍都有多核CPU的时代,坐在那里等待毫无意义,你完全可以在另一个处理器内核上干其他的工作,同时计算机完成耗时任务的时候通知你。这样你可以同时完成其他工作,这就是异步编程的出发点。
具体来说,我们在web编程中,当浏览器里面的一个web应用进行密集运算还没有把控制权返回给浏览器的时候,整个浏览器就像冻僵了一样,即出现了阻塞。在实际应用中,这种情况可能是因为向后端请求数据,然后对得到的数据进行处理并展示,在等待数据的时候,就会发生阻塞。而会发生阻塞是因为JavaScript传统上是单线程的,即每个任务顺序执行,只有前面的结束了,后面的才能开始。
Main thread: Task A Task B
Promise: |__async operation__|
如上,在异步中,任务B会在任务A执行完之后被唤醒执行,而在这个过程中主线程可以进行其他渲染任务
异步JavaScript
我们先来看同步的JavaScript,即代码顺序执行
const btn = document.querySelector('button');
btn.addEventListener('click', () => {
alert('You clicked me!');
let pElem = document.createElement('p');
pElem.textContent = 'This is a newly-added paragraph.';
document.body.appendChild(pElem);
});
这个例子里,当我们按下按钮之后,直到关闭alter,后面的页面渲染都没有进行(这里alter只是为了演示,实际应用中不会用到它)
还有一个更实际的例子,我们要请求一张图片,然后将它显示在页面上
var response = fetch('myImage.png');
var blob = response.blob();
因为你不知道下载图片会多久,所以第二行代码执行的时候可能报错,因为图像还没有就绪。取代的方法就是,代码必须等到 response 返回才能继续往下执行,而这个时候,你的页面就会看上去像卡住了
回调函数(callbacks)
回调函数即作为参数传递给那些在后台执行的其他函数, 当那些后台运行的代码结束,就调用callbacks函数,通知你工作已经完成,或者其他有趣的事情发生了。
比如上面的addEventListener就是一个回调,他在监听的事件发生的时候被调用。但是注意,不是所有的回调函数都是异步的,比如用forEach来遍历数组时,传入的函数就是同步的。
由于我们在后面很少单纯用回调来实现异步(这种写法比较古老而且有一些缺点),这里只展示一个简单的例子
setTimeout:在指定的时间后执行一段代码
可以思考一下在同步和异步的情况下这段代码的输出是什么样的
setTimeout(()=>{console.log('hi');},20000);
console.log('bye');
有关回调函数,还有一个比较有意思的回调地狱的情况会出现
Promise
Promises 是新派的异步代码,现代的web APIs经常用到。先来看一个展示Promise基本语法的例子
fetch('products.json').then(function(response) {
return response.json();
}).then(function(json) {
products = json;
initialize();
}).catch(function(err) {
console.log('Fetch problem: ' + err.message);
});
这里的fetch() 返回一个 promise. promise 是表示异步操作完成或失败的对象。可以说,它代表了一种中间状态。 本质上,这是浏览器说“我保证尽快给您答复”的方式,因此得名“promise”。而在上面的代码中,跟在promise后面的是
- 两个
then()块。两者都包含一个回调函数,如果前一个操作成功,该函数将运行,并且每个回调都接收前一个成功操作的结果作为输入,因此可以继续对它执行其他操作。每个.then()块返回另一个promise,这意味着可以将多个.then()块链接到另一个块上,这样就可以依次执行多个异步操作。 - 如果其中任何一个
then()块失败,则在末尾运行catch()块——与同步try...catch类似,catch()提供了一个错误对象,可用来报告发生的错误类型。
Promise 对象本质上表示的是一系列操作的中间状态,或者说是未来某时刻一个操作完成或失败后返回的结果。Promise并不保证操作在何时完成并返回结果,但是保证在当前操作成功后执行您对操作结果的处理代码,或在操作失败后,优雅地处理操作失败的情况。
对比回调,Promise的优点可以从下面的代码中看出(模拟按顺序处理披萨订单)
回调的实现是这样的,就像上面的回调地狱,可读性差
chooseToppings(function(toppings) {
placeOrder(toppings, function(order) {
collectOrder(order, function(pizza) {
eatPizza(pizza);
}, failureCallback);
}, failureCallback);
}, failureCallback);
而用Promise我们可以这样实现
chooseToppings()
.then(toppings => placeOrder(toppings))
.then(order => collectOrder(order))
.then(pizza => eatPizza(pizza))
.catch(failureCallback);
async await
async和await是在ECMAScript 2017中添加的promises的语法糖,使得异步代码更易于编写和后续阅读。
-
首先,我们使用
async关键字,将它放在函数声明之前,将其转换为async function。异步函数是一个知道怎样预期 await 关键字可用于调用异步代码可能性的函数。而async函数调用返回的是一个promiseconst hello = async () => { return "Hello" }; hello(); //Promise {<resolved>: "Hello"}当然这个Promise可以像之前提到的一样后接
.then()等等来使用。我们只需要在需要异步执行的函数前添加async关键字,JavaScript引擎就可以优化你的程序 -
与
awiat关键字结合可以体现出他们的真正优势,awiat可以用在异步函数中,他会使得暂停代码在该行上,直到promise完成,然后返回结果值。可以在调用任何返回Promise的函数时使用await。
我们通过一个例子来看下它与Promise的区别
Promise
fetch('coffee.jpg')
.then(response => response.blob())
.then(myBlob => {
let objectURL = URL.createObjectURL(myBlob);
let image = document.createElement('img');
image.src = objectURL;
document.body.appendChild(image);
})
.catch(e => {
console.log('There has been a problem with your fetch operation: ' + e.message);
});
async await
async function myFetch() {
try {
let response = await fetch('coffee.jpg');
let myBlob = await response.blob();
let objectURL = URL.createObjectURL(myBlob);
let image = document.createElement('img');
image.src = objectURL;
document.body.appendChild(image);
} catch(e) {
console.log(e);
}
}
myFetch();
使用async、await会使你的代码看起来更像是同步代码,读起来也十分容易理解,因为他实际上就是在顺序执行,但是在等待await的时候并不会产生阻塞,影响其他渲染任务
TypeScript
JavaScript 是一个不具有强类型的动态语言,这赋予了它极大的灵活性,但也带来了开发和生产上可能存在的问题。TypeScript 是 JavaScript 的超集,使得 JavaScript 中的每一个变量和函数都具有和 C 一样的类型定义。你可以利用 TypeScript 在编译期进行类型检查,提前发现错误。我们在使用ts的时候,最终还是会将其编译为js代码,但是在编译的时候会进行静态类型检查如果发现有错误,编译的时候就会报错。
类型注解
TypeScript里的类型注解是一种轻量级的为函数或变量添加约束的方式。我们可以简单的使用:来添加类型注解,例如
function greeter(person: string) {
return "Hello, " + person;
}
let user = [0, 1, 2];
greeter(user);
//greeter.ts(7,26): error TS2345: Argument of type 'number[]' is not assignable to parameter of type 'string'.
在此展示最简单的基础类型
//布尔值
let isDone: boolean = false;
//数字
let decLiteral: number = 6;
let hexLiteral: number = 0xf00d;
let binaryLiteral: number = 0b1010;
let octalLiteral: number = 0o744;
//字符串
let name: string = "bob";
name = "smith";
let sentence: string = `Hello, my name is ${ name }.`
//数组
let list: number[] = [1, 2, 3];
let list: Array<number> = [1, 2, 3];
//元组,表示一个已知元素数量和类型的数组,各元素的类型不必相同
// Declare a tuple type
let x: [string, number];
// Initialize it
x = ['hello', 10]; // OK
// Initialize it incorrectly
x = [10, 'hello']; // Error
//枚举
enum Color {Red, Green, Blue}
let c: Color = Color.Green;
//Void,表示一个函数没有返回值
function warnUser(): void {
console.log("This is my warning message");
}
//Null 和 Undefined
let u: undefined = undefined;
let n: null = null;
//他们是所有类型的子类型
// 这样不会报错
let num: number = undefined;
这里单独说一下any,任意值(Any)用来表示允许赋值为任意类型,并且你可以对其访问任何属性,调用任何方法。它主要用于为那些在编程阶段还不清楚类型的变量指定一个类型,比如来自用户输入或第三方代码库的内容。如果你在声明变量的时候没有指定类型和初值,他会被识别为any类
let myFavoriteNumber: any = 'seven';
myFavoriteNumber = 7;
let something;
something = 'seven';
something = 7;
下面给出指定函数类型的例子
//完整
let myAdd: (x: number, y: number) => number =
function(x: number, y: number): number { return x + y; };
//推断
// myAdd has the full function type
let myAdd = function(x: number, y: number): number { return x + y; };
// The parameters `x` and `y` have the type number
let myAdd: (baseValue: number, increment: number) => number =
function(x, y) { return x + y; };
ts也可以设定可选参数以及参数默认值,可选参数在参数后加?即可
let myAdd = function(x: number = 1, y?: number): number { ...};
类型断言
有时候你会遇到这样的情况,你会比TypeScript更了解某个值的详细信息。 通常这会发生在你清楚地知道一个实体具有比它现有类型更确切的类型。通过类型断言这种方式可以告诉编译器,“相信我,我知道自己在干什么”。
类型断言的两种方式为
let someValue: any = "this is a string";
let strLength1: number = (<string>someValue).length;
let strLength2: number = (someValue as string).length;
联合类型
联合类型(Union Types)表示取值可以为多种类型中的一种。联合类型使用 | 分隔每个类型。
let myFavoriteNumber: string | number;
myFavoriteNumber = 'seven';
myFavoriteNumber = 7;
当 TypeScript 不确定一个联合类型的变量到底是哪个类型的时候,我们只能访问此联合类型的所有类型里共有的属性或方法
function getLength(something: string | number): number {
return something.length;
}
// index.ts(2,22): error TS2339: Property 'length' does not exist on type 'string | number'.
// Property 'length' does not exist on type 'number'.
这时候我们就可以用到上面的类型断言
类型别名
我们使用 type 创建类型别名,类型别名常用于联合类型
type Name = string;
type NameResolver = () => string;
type NameOrResolver = Name | NameResolver;
接口
TypeScript的核心原则之一是对值所具有的结构进行类型检查。 它有时被称做“鸭式辨型法”或“结构性子类型化”。 在TypeScript里,接口的作用就是为这些类型命名和为你的代码或第三方代码定义契约。简单的说,在 TypeScript 中,我们使用接口(Interfaces)来定义对象的类型。
interface Person {
name: string;
age: number;
}
let tom: Person = {
name: 'Tom',
age: 25
};
let jack: Person = {
name: 'Jack'
};
// index.ts(6,5): error TS2322: Type '{ name: string; }' is not assignable to type 'Person'.
// Property 'age' is missing in type '{ name: string; }'.
当然也可以加入可选属性,上面的错误可以这样解决
interface Person {
name: string;
age?: number;
}
let jack: Person = {
name: 'Jack'
};
泛型
这个概念和C/C++里的模板比较相似,由于刚学过在此不作讲解,具体可以在读代码的时候学习
template <typename T>
function identity<T>(arg: T): T {
return arg;
}
let myIdentity: <T>(arg: T) => T = identity;
EESAST前端代码中的一个例子
const columns: ColumnProps<ITeam>[] = [];
模块
任何声明(比如变量,函数,类,类型别名或接口)都能够通过添加export关键字来导出。
可以在声明的时候直接导出
export interface StringValidator {
isAcceptable(s: string): boolean;
}
export const numberRegexp = /^[0-9]+$/;
export class ZipCodeValidator implements StringValidator {
isAcceptable(s: string) {
return s.length === 5 && numberRegexp.test(s);
}
}
也可以在声明之后的任意位置导出,并且可以重命名
class ZipCodeValidator implements StringValidator {
isAcceptable(s: string) {
return s.length === 5 && numberRegexp.test(s);
}
}
export { ZipCodeValidator };
export { ZipCodeValidator as mainValidator };
在导入的时候,可以直接导入,也可以进行重命名
import { ZipCodeValidator } from "./ZipCodeValidator";
import { ZipCodeValidator as ZCV } from "./ZipCodeValidator";
每个模块都可以有一个default导出。 默认导出使用 default关键字标记;并且一个模块只能够有一个default导出。对于default模块在导入的时候不必加大括号,而且可以直接重命名
//OneTwoThree.ts
export default "123";
import num from "./OneTwoThree";
React + antd 入门教程
本节内容相关代码请访问react-tutorial,文档
说明
本节将使用 Yarn 作为包管理,用 Node.js 运行一个 React App,结合 antd 组件从头开始搭建一个小游戏作为入门。会介绍以下内容:
- 什么是 Node.js?如何使用 Yarn 进行包管理?
- 如何初始化一个使用 TypeScript 的 React 应用?
- React 和 antd 分别是干什么的?
- 前端需要做些什么?
小游戏借鉴了Rust 文档。对优质文档和启发灵感表示感谢。
相关依赖
本节内容的详细文档提供了使用 CodeSandbox 的在线环境与各阶段代码,如果读者自行配置环境遇到困难,可以尝试使用。出于一些原因,CodeSandbox 中的代码会与文档有些微的区别,但不涉及到本节说要讲解内容的重点。
- Node.js 和 Yarn:请参阅文档进行安装
- React
- antd
后端技术栈入门
本讲主要为使用Node.js结合Express和Mongo的RESTful后端开发入门指南。准备工作需要安装以下工具并设置环境变量。
本讲演示样例为清华电子系学生科协网站在2020年5月1日前的前后端代码(现已从REST迁移至GraphQL),代码开源于前端代码与后端代码,代码也已复制至本仓库中,可在协议许可的范围内学习使用。
本讲主要介绍:
- RESTful
- Node.js
- Express
- MongoDB
- Postman使用
详情请查看课程代码及其文档。
GraphQL, Hasura, PostgreSQL, Apollo
本节介绍 GraphQL、Hasura、PostgreSQL(关系型数据库)、Apollo,这是目前网站主要拉取数据的方案。
四个部分大致是如下图构成数据查询流程。即编写查询相关的 GraphQL 语句,Apollo 会生成相应的 TS 代码,经编译后运行在 Node.js 上,使用 GraphQL 的形式与 Hasura 进行交互,由 Hasura 访问 PostgreSQL 数据库存取数据。

接下来,将逐步讲解以下概念:
- 什么是“关系型数据库”?SQL 又是什么?
- 从 SQL 到 GraphQL
- 使用 Hasura+PostgreSQL 来管理数据
- 使用 Apollo 编写查、增、删、改
相关链接:
关系型数据库与 SQL
数据库,顾名思义是存储数据的。我们常用实体-联系的方式来对数据进行抽象,其中实体是客观存在并可相互区分的事物,而联系指的是不同(类)实体之间的关系。关系型数据库指的是使用关系模型来存储数据。

不同实体间的联系一般分为“一对一”、“一对多”、“多对多”三种,可以借助三个例子理解:
- 一对一:一个班有一个班主任,一个班主任负责一个班
- 一对多:一个作者可以写多篇文章
- 多对多:一个用户可以关注多个用户,同时被多个用户关注
而关系模型则是使用一张表来存储数据,比如
| 用户信息 | ||
|---|---|---|
| id | 用户名 | 性别 |
| 1 | 张三 | 男 |
| 2 | 古河渚 | 女 |
| 3 | 秀吉 | 秀吉 |
表中每列是一个属性,每行是一个实体的数据(也称元组)。总应有至少一个属性可以唯一标识元组,称为候选码,选其中一个作为主码。部分属性可能是其他关系表中的主码,称为外码。我们会在接下来的例子中看到这些“码”。
SQL(Structured Query Language,结构化查询语言)是用来对数据进行查询、添加、删除、更改的语言,这里只简单介绍查询功能。假定我们有三个表分别存学生、课程、学生-课程,我们可以使用如下的 SQL 语句进行查询:
查询全体学生的学号和姓名
SELECT stu_no, stu_name
FROM Student;
查选修C1课程的学生的学号和成绩,并按分数降序排列
SELECT stu_no, grade
FROM StudentCourse
WHERE course_no='C1'
ORDER BY grade DESC;
更多有关 SQL 的内容不是培训重点,建议感兴趣的同学自行学习。
GraphQL
SQL 较为古老,对于数据量大且关系复杂的查询不够直观,GraphQL 则是一个更为直观的查询语言。
在 JS / json 中,我们使用类似的结构来表示对象
[
{
"username": "Zhang San",
"gender": "male"
},
{
"username": "Nagisa",
"gender": "female"
}
]
我们可以使用极为相似的 GraphQL 语句来查询
query {
user {
username
}
}
得到相应的 json 结果
{
"data": {
"user": [
{
"username": "Zhang San"
},
{
"username": "Nagisa"
}
]
}
}
一个更为复杂的例子
query GetArticleFeeds(
$limit: Int = 2
$cursor: timestamptz!
$authorId: String
$title: String
$alias: String
$abstract: String
$content: String
) {
article_public(
limit: $limit
where: {
_and: [
{ created_at: { _lte: $cursor } }
{ authorId: { _eq: $authorId } }
{ title: { _ilike: $title } }
{ alias: { _ilike: $alias } }
{ abstract: { _ilike: $abstract } }
{ content: { _ilike: $content } }
]
}
order_by: { created_at: desc }
) {
id
alias
title
abstract
views
created_at
author {
username
}
article_tags {
tag {
tag_name
}
}
article_likers_aggregate {
aggregate {
count(distinct: true)
}
}
}
}
这是正在开发的 Weekly 用来获取文章信息的语句(可能会有更改)。最前面的$加字符串表示查询语句中使用的变量,后面加感叹号表示该项必须存在。这些变量在下方的where中使用,用来限制查询结果。最后面的花括号中包含的内容是要得到的数据,其中author、article_tags和articl_likers_aggregate是利用外码获取对应的作者信息、标签信息、喜欢文章的用户的统计信息。
用于更改(增删)的语句则使用mutation关键字
mutation InsertArticle(
$abstract: String = ""
$alias: String!
$content: String!
$authorId: String!
$title: String!
$tags: [article_tag_insert_input!]! = []
) {
insert_article_one(
object: {
abstract: $abstract
alias: $alias
content: $content
authorId: $authorId
title: $title
article_tags: {
data: $tags
on_conflict: { constraint: article_tag_pkey, update_columns: tag_id }
}
}
on_conflict: { constraint: article_alias_key, update_columns: [] }
) {
id
}
}
这段语句将基于给定的变量,创建一篇文章,并返回文章的 id。
Hasura 和 PostgreSQL
前面讲的 GraphQL 看上去很美化,但要自行实现相应的 API 不是一件容易的事,因此我们选用 Hasura GraphQL Engine。
Hasura 是开源的 GraphQL 引擎,默认使用 PostgreSQL 数据库存储数据,可以使用其提供的 console 页面创建数据表、增删改数据、设置操作权限、测试 GraphQL 语句。下面将从安装开始“浏览”基本使用。
安装
参照官方文档,我们使用 docker 进行安装。首先修改官方提供的docker-compose.yaml
version: "3.6"
services:
postgres:
image: postgres:latest
container_name: postgres
restart: always
volumes:
- ~/data/postgres:/var/lib/postgresql/data
ports:
- "5432:5432"
environment:
POSTGRES_PASSWORD: postgrespassword
graphql-engine:
image: hasura/graphql-engine:latest
container_name: hasura
ports:
- "23333:8080"
depends_on:
- "postgres"
restart: always
environment:
HASURA_GRAPHQL_DATABASE_URL: postgres://postgres:postgrespassword@postgres:5432/postgres
HASURA_GRAPHQL_ENABLE_CONSOLE: "true" # set to "false" to disable console
HASURA_GRAPHQL_ENABLED_LOG_TYPES: startup, http-log, webhook-log, websocket-log, query-log
## uncomment next line to set an admin secret
# HASURA_GRAPHQL_ADMIN_SECRET: myadminsecretkey
注意其中需要修改的几处地方:
- 容器端口绑定宿主机端口是否会冲突
- PostgreSQL 的密码是否需要设置
- Hasura 的密码是否需要设置(默认不设置)
在修改好后的docker-compose.yaml所在路径使用如下命令拉取镜像并启动容器
docker-compose up -d
启动后,我们使用docker ps -a可以查看容器状态(类似下方所示)
CONTAINER ID IMAGE ... CREATED STATUS PORTS ...
097f58433a2b hasura/graphql-engine ... 1m ago Up 1m 0.0.0.0:23333->8080/tcp ...
b0b1aac0508d postgres ... 1m ago Up 1m 0.0.0.0:5432->5432/tcp ...
现在访问localhost:23333/console可以进入 Hasura 的控制界面
Hasura 提供许多功能,我们主要使用GRAPHIQL和DATA两个页面的功能
创建与管理数据
在DATA页面可以创建“关系表”,比如创建一个user:
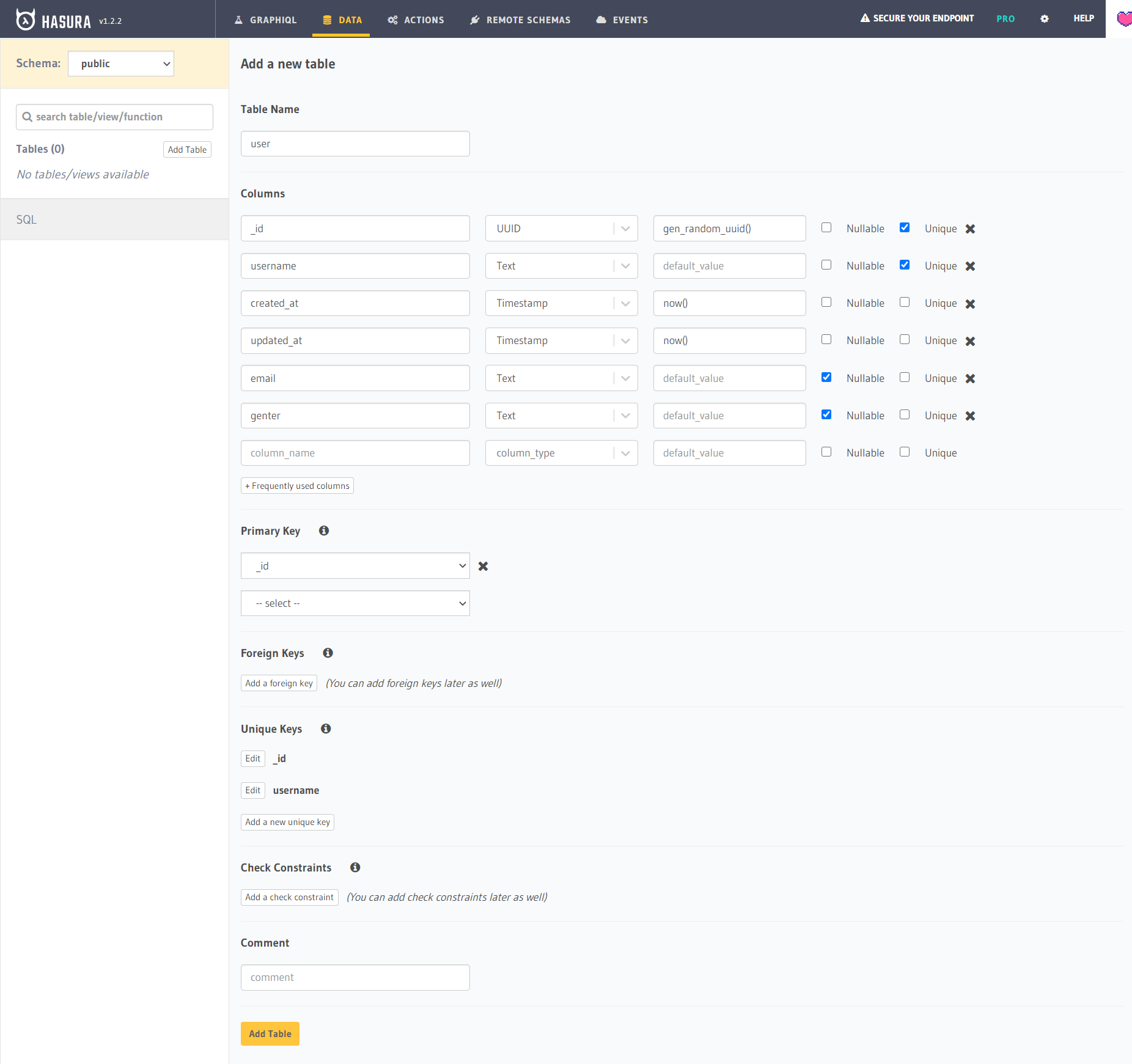
这里填入了 6 个属性,其中_id为主码,使用数据库的 uuid 生成器得到。username、email、gender皆为字符串,其中username也是不可重复的(我们称为候选码),而email和gender则是可以为空的普通属性。created_at和updated_at则是使用+ Frequently used columns添加的,分别会根据创建和更改时的时间自动添加。
我们再来创建一个article表,加入作者的_id作为外码:
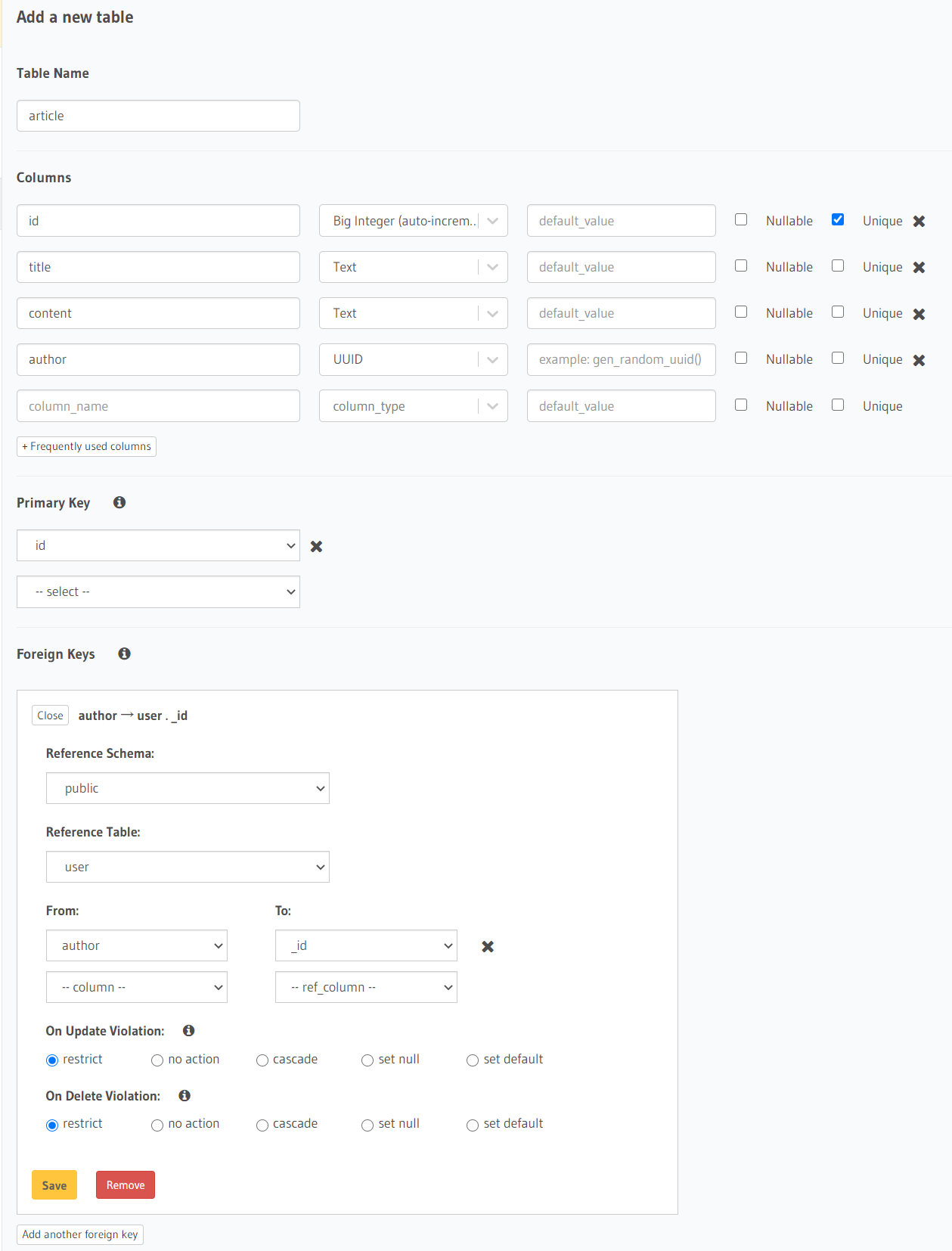
这里将author的值设为 uuid 类型,并与user._id严格一致。我们点开article的Relationships可以看到推荐的关系设置:
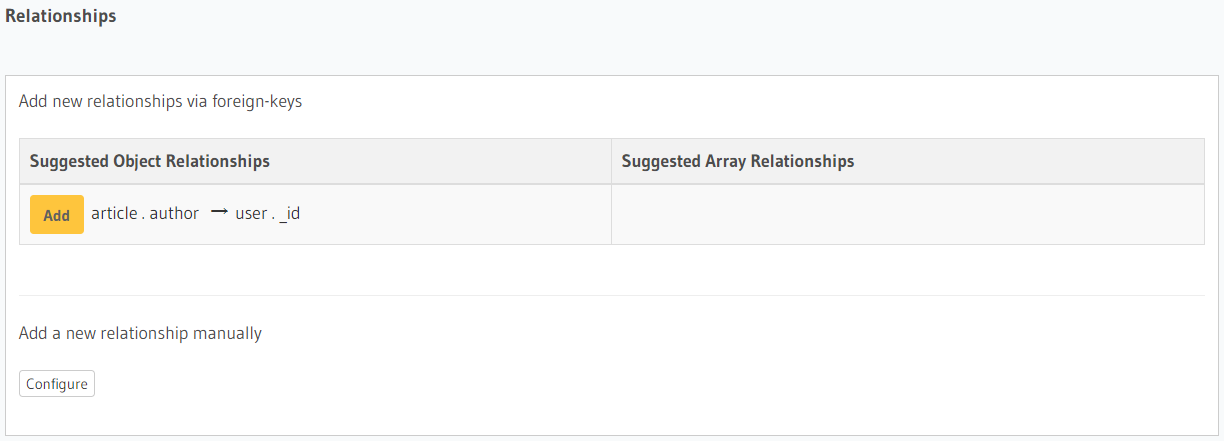
这里推荐添加Object relationships,而在user的Relationships可以看到推荐Array relationships。点击添加便是告诉 Hasura 这两个表之间是一对多的关系,即一个user可以有多篇article。我们可以在GRAPHIQL页面试着写一下查询语句:
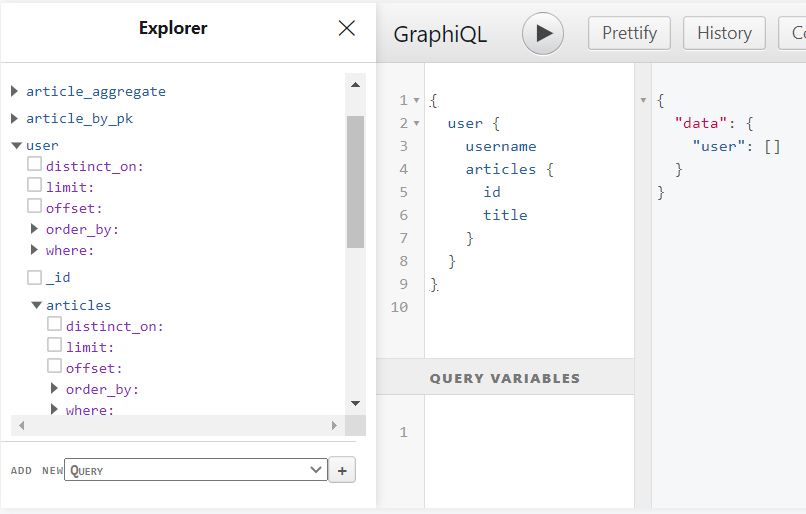
一般限制条件不太复杂的查询或者更改操作,都可以使用最左侧的 Explorer 勾选需要的部分,由 Hasura 生成中间的语句,点击“执行”按钮可以在右边看到结果。这里因为还没有添加数据,所以是空的。
对于更为复杂的关系,比如“喜欢一篇文章”这种多对多关系,我们需要再创建一个表,只有article_id和user_id两个属性,一起作为主码,又同时是外码。当表中存在这样的数据时,就表明某用户喜欢某篇文章。
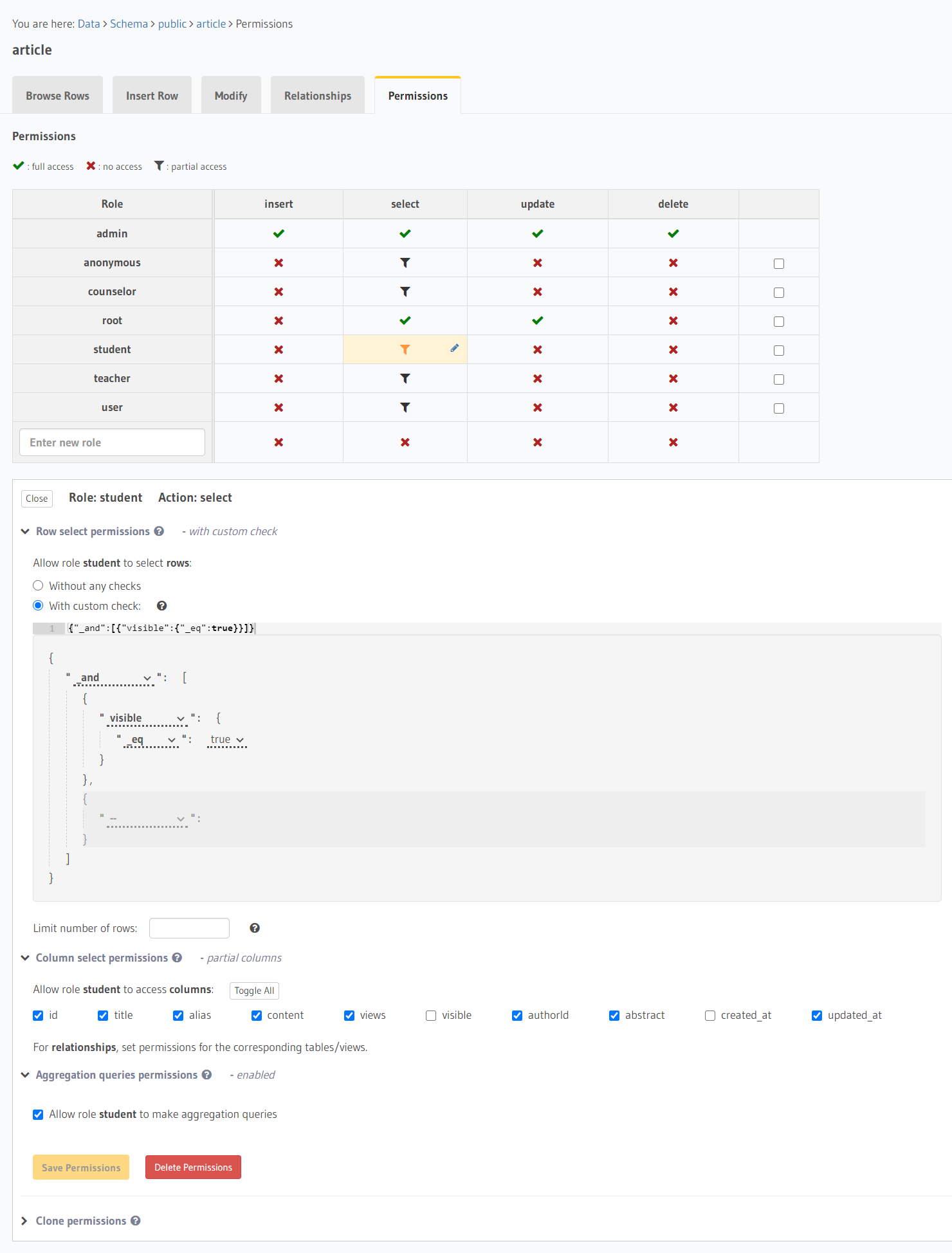
最后我们再看一下“权限控制”。在表的Permissions页面可以设置不同身份用户的插入、查询、更改与删除权限。目前 Hasura 提供的权限设置自由度较小,如果要设置非常复杂的权限,需要通过添加数据表的view再给其设置权限等方法来实现。具体细节可以参看Multiple column + row permissions for the same role
Apollo
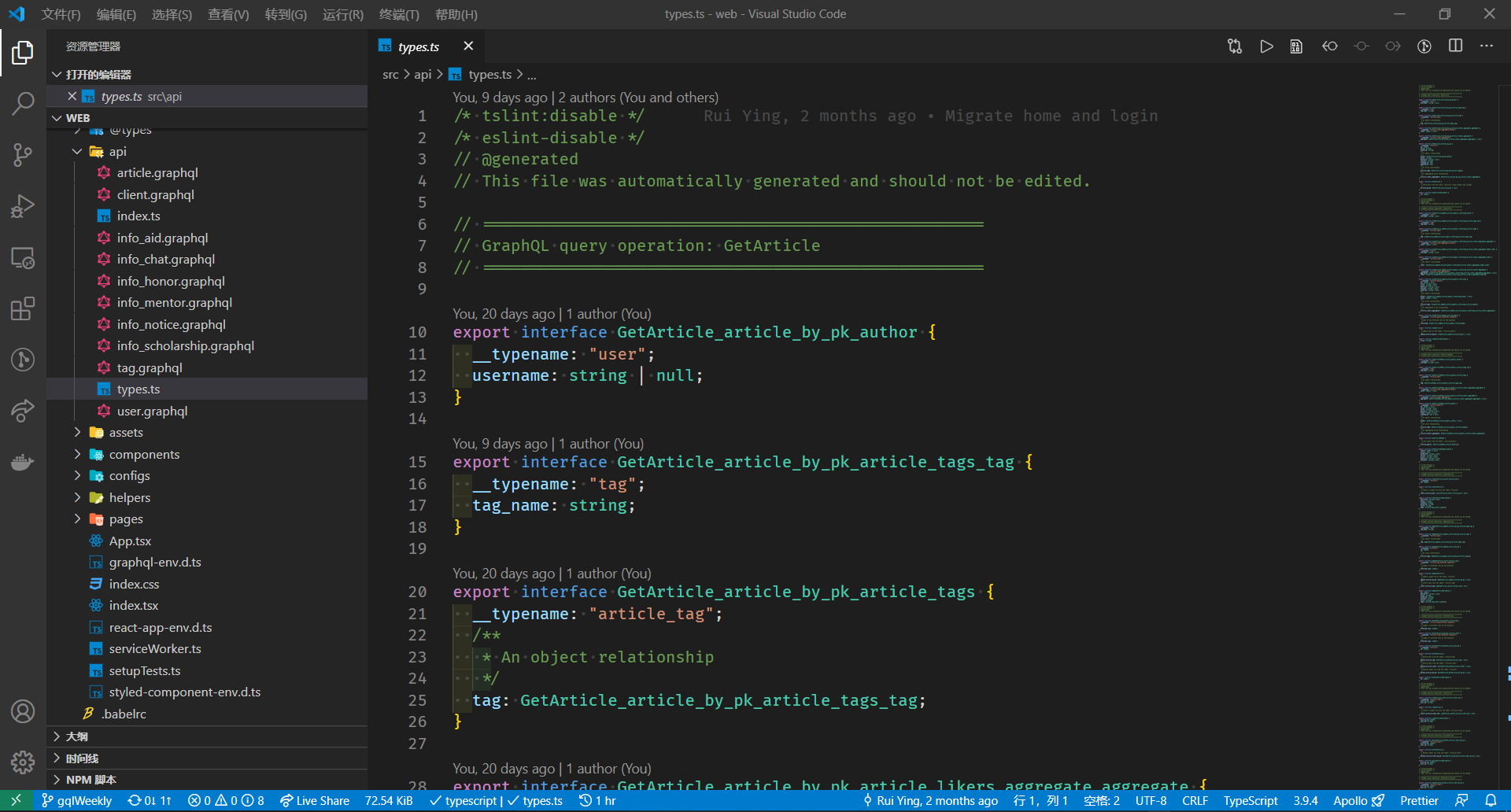
我们这里说的 Apollo 主要指的是 Apollo Client (React),实现了拉取并管理数据的功能。Apollo 本身会根据配置好的服务端的数据,将本地写好的GraphQL语句编译为typescript接口。
目前的前端项目中,我们在src/api文件夹下编写*.graphql文件,即填写在 Hasura 中测试过得到需要结果的query或mutation语句。之后使用 Apollo 的codegen编译为相应的接口,供前端页面拉取数据使用。
我们使用 Apollo 提供的useQuery和useMutation来进行数据的获取和更改。参考官方文档使用useQuery:
const GET_DOG_PHOTO = gql`
query Dog($breed: String!) {
dog(breed: $breed) {
id
displayImage
}
}
`;
function DogPhoto({ breed }) {
const { loading, error, data } = useQuery(GET_DOG_PHOTO, {
variables: { breed },
});
if (loading) return null;
if (error) return `Error! ${error}`;
return (
<img src={data.dog.displayImage} style={{ height: 100, width: 100 }} />
);
}
观察到有一个变量,存的是 GraphQL 的语句,并将这个变量传入useQuery,返回的是data、loading和error三项。顾名思义,是返回的数据、加载状态与是否错误。迁移到typescript是类似这样的:
query GetUser($_id: String!) {
user(where: { _id: { _eq: $_id } }) {
_id
id
name
username
department
class
phone
email
}
}
import { GetUser as GET_USER } from "../api/user.graphql";
import { GetUser, GetUserVariables } from "../api/types";
const { data, loading, error } = useQuery<GetUser, GetUserVariables>(GET_USER, {
variables: { _id: userData?._id! },
});
这里从user.graphql中导入了GetUser的片段并起别名叫GET_USER,并从 Apollo 生成的接口中导入GetUser和GetUserVariables,即告诉useQuery要使用GET_USER的形式发送请求。之后每次渲染useQuery所在的组件时,便会执行这个请求拉取用户信息。
而mutation所用的useMutation则是会创建一个函数,显式调用以进行更改的操作。
mutation UpdateUser(
$_id: String!
$id: bigint!
$username: String
$phone: String
$name: String
$department: String
$class: String
$email: String
) {
update_user(
where: { _id: { _eq: $_id } }
_set: {
id: $id
username: $username
phone: $phone
name: $name
department: $department
class: $class
email: $email
}
) {
affected_rows
}
}
import { UpdateUser as UPDATE_USER } from "../api/user.graphql";
import { UpdateUser, UpdateUserVariables } from "../api/types";
const [
updateUser,
{ data: updateData, loading: updating, error: updateError },
] = useMutation<UpdateUser, UpdateUserVariables>(UPDATE_USER);
下面我们来看查询和更改的例子。我们在数据库里存了很多文章,现在我们要获取并用一个列表展示它们。当用户点击文章时会跳转到相应页面进行阅读,同时更改数据库中该文章的view属性(加 1)。
const { data, loading, error } = useQuery<
GetArticleFeeds,
GetArticleFeedsVariables
>(GET_ARTICLE_FEEDS, {
variables: { limit: 5, cursor: cursor },
});
useEffect(() => {
if (data) {
setArticles(
data.article_public.map((article) => {
return {
title: article.title!,
alias: article.alias!,
abstract: article.abstract!,
author: article.author?.username!,
likes: article.article_likers_aggregate.aggregate?.count!,
views: article.views!,
tags: article.article_tags.map((t) => t.tag.tag_name),
};
})
);
}
}, [data]);
return (
<Row>
<Col span={4}></Col>
<Col span={16}>
<List
dataSource={articles}
renderItem={(item) => {
return (
<Link to={`/weekly/explore/${item.alias}`}>
<ArticleFeedCard article={item} />
</Link>
);
}}
></List>
</Col>
<Col span={4}></Col>
</Row>
);
这里使用useQuery,基于cursor(用来确定获取文章的时间戳,初始化为当前时间)拉取 5 篇文章,并使用map变为<ArticleFeedCard />组件接收的参数。
const [
viewArticle,
{ data: articleData, loading: articleLoading, error: articleError },
] = useMutation<ViewArticle, ViewArticleVariables>(VIEW_ARTICLE);
useEffect(() => {
viewArticle({
variables: { alias: alias },
});
}, [alias, viewArticle]);
useEffect(() => {
if (articleData && !articleError && articleData.update_article_public) {
setArticle(articleData?.update_article_public?.returning[0]);
setContentHtml(
md2wx.renderHtml(
articleData?.update_article_public?.returning[0].content!
)
);
}
}, [articleData, articleError]);
在文章的阅读页面,则是使用mutation同时修改view并获取文章的内容,再存储到组件的状态中,以备其他功能需要。
Apollo 的简短介绍到这里就结束了,对于更深内容感兴趣的同学可以自行查阅其文档学习。
写在最后
GraphQL 整体上是比较新的一种技术,直观是其优势。同时,也因为较新,轮子会相对少一些,有中文文档的轮子就更少了。此外,部分轮子还在迅速的演进,会有较多的BREAKING CHANGE,有可能代码刚写完,不小心更新一下依赖就挂掉了(笑)。为了减少这种更新带来的麻烦,我们一般会使用“机器人”来尝试更新依赖,即持续集成。具体内容将在下一节中讲解。
Web测试 + CI/CD
Mocha & Chai
Mocha是Node.js上的JavaScript测试框架。(参见官方文档)
Chai是断言库。
测试脚本里面应该包括一个或多个describe块,每个describe块应该包括一个或多个it块。describe块为test suite,it块为test case。
before(), after(), beforeEach(), afterEach()为hooks,done可用于异步回调。only和skip方法。(此处略,可自学)
var assert = require('assert');
describe('Array', function () {
describe('#indexOf()', function () {
it('should return -1 when the value is not present', function () {
assert.equal([1, 2, 3].indexOf(4), -1);
});
});
});
CI/CD
CI(持续集成,Continuous Integration):是将所有软件工程师对于软件的工作副本持续集成到共享主线(mainline)的一种举措。在测试驱动开发(TDD)的作法中,通常还会搭配自动单元测试。
(极限编程中,测试驱动开发指先完成测试代码,再快速写代码完成功能。先实现功能,在测试的辅助下,快速实现其功能;再重构,在测试的保护下,通过去除冗余的代码,提高代码质量。)
在模块化的开发中,各人独立开发不同的模块时,持续集成也起到很大作用。
CD(持续交付,Continuous Delivery / 持续部署,Continuous Deployment):持续部署指在软件开发流程中,以自动化方式,频繁而且持续性的,将软件部署到生产环境中。持续交付与持续部署的区别在于,持续交付指所有的变更都可以被部署到生产环境中,但是出于业务考虑,可以选择不部署。
Common practices
- Maintain a code repository
- Automate the build
- Make the build self-testing
- Everyone commits to the baseline every day
- Every commit (to baseline) should be built
- Every bug-fix commit should come with a test case
- Keep the build fast
- Test in a clone of the production environment
- Make it easy to get the latest deliverables
- Everyone can see the results of the latest build
- Automate deployment

现有的清华电子系学生科协网站的CI/CD方式是:通过GitHub Actions或Travis CI实现持续集成,并将代码编译后推至docker hub,由服务器端的watchtower容器自动检测镜像的更新并自动拉取运行,实现持续部署。
此讲中我们跟随GitHub Learning Lab的一个教程来学习持续集成,实验仓库公开。另外,清华大学人工智能挑战赛主网站的github actions workflow如下所示,供参考我们的CI/CD流程(科协官网使用Travis CI,可自行参阅代码)。
name: CI
on: [push, pull_request]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v1
- run: npm i -g yarn
- name: yarn install, build, and test
run: |
yarn install
yarn test
yarn build
env:
CI: true
- name: docker build
env:
CONTAINER_IMAGE_NAME: ${{ secrets.CONTAINER_IMAGE_NAME }}
DOCKER_REGISTRY_URL: ${{ secrets.DOCKER_REGISTRY_URL }}
run:
docker build -t $DOCKER_REGISTRY_URL/$CONTAINER_IMAGE_NAME:latest .
- name: docker login
uses: azure/docker-login@v1
with:
username: ${{ secrets.DOCKER_USERNAME }}
password: ${{ secrets.DOCKER_PASSWORD }}
- name: docker push
env:
CONTAINER_IMAGE_NAME: ${{ secrets.CONTAINER_IMAGE_NAME }}
DOCKER_REGISTRY_URL: ${{ secrets.DOCKER_REGISTRY_URL }}
run: docker push $DOCKER_REGISTRY_URL/$CONTAINER_IMAGE_NAME:latest
- name: docker logout
uses: azure/container-actions/docker-logout@master
Linux 入门实操
基本上是翻译了下missing-semester的 1、3 讲
写完这个发现 missing-semester 有中文版orz
说明
此处的文档为本次课程的 linux 实操部分,其他课件请见此处
Shell 基础
shell 使用
打开 shell 之后首先看到这样的提示符
zxdclyz@Lyz:~$
用户名@设备名:当前路径,~代表 home 家路径
此时就可以输入命令了
zxdclyz@Lyz:~$ date
Sat Jun 20 20:07:17 CST 2020
zxdclyz@Lyz:~$
通过输入 date 运行了 date 这个打印日期和时间的程序,然后提示符重新出现,告诉我们可以输入下一条命令
另一个十分基础的命令是 echo
zxdclyz@Lyz:~$ echo hello world
hello world
echo 的作用是直接打印它的参数,在 shell 中,命令是以空格隔断的,第一个词指定运行的程序,后面的是参数,如果想要在一个参数中包括空格,可以使用'或者",也可以用\(space)
zxdclyz@Lyz:~$ echo 'hello world'
hello world
zxdclyz@Lyz:~$ echo hello\ world
hello world
不过在 echo 中看不出区别 orz
那么我们输入 date、echo 运行的是什么程序呢?shell 也是一个编程环境,类似 python,其中也有变量,如果输入了程序关键字之外的字段,shell 会去查找$PATH环境变量中的路径
zxdclyz@Lyz:~$ echo $PATH
/usr/local/sbin:/usr/local/bin
其中的路径用:分隔,可以用which命令查看运行的程序所在路径
zxdclyz@Lyz:~$ which echo
/bin/echo
如果程序所在路径不在环境变量里,也可以直接使用其完整路径来调用
zxdclyz@Lyz:~$ /bin/echo eesast
eesast
文件系统
有关文件操作,pwd显示当前路径,cd改变路径,ls打印当前目录中的文件,.指当前目录,..指上级目录
zxdclyz@Lyz:~/tutorial$ ls
a.txt b.py c.js
zxdclyz@Lyz:~/tutorial$ cd ../
zxdclyz@Lyz:~$ pwd
/home/zxdclyz
zxdclyz@Lyz:~$
使用cd -可以跳转到刚才所在的路径,用mkdir创建文件夹,mv移动文件,cp复制文件,rm删除文件,touch创建文件
有关文件权限,参考课件
查看命令参数
可以使用man command来进入手册页,也可以直接使用--help 参数查看
zxdclyz@Lyz:/bin$ ls --help
...
zxdclyz@Lyz:/bin$ man ls
连接程序
在 shell 中,程序也有输入流和输出流,我们可以用> file和< file来重新引导流
zxdclyz@Lyz:~/tutorial$ echo hello > hello.txt
zxdclyz@Lyz:~/tutorial$ echo bye >> hello.txt
使用>>可以进行追加写
另一个十分有用的工具是 pipe|,它可以连接两个命令,将前一个命令的输出当做后一个命令的输入
zxdclyz@Lyz:~/tutorial$ cat hello.txt
hello
bye
hello world
zxdclyz@Lyz:~/tutorial$ cat hello.txt|grep world
hello world
Vim 极简入门
如果你在使用服务器并且想简单地对一个文件进行编辑,使用 vim 是十分方便的(大量编辑我倾向于使用 VSCode 等远程连接),vim 本身拥有十分强大的功能,但我自己也并不会,所以只在此展示最基础的用法
使用vim file打开文件进行编辑
刚进入时处于正常模式,而 vim 中有这些模式
- Normal: for moving around a file and making edits
- Insert: for inserting text
- Replace: for replacing text
- Visual (plain, line, or block): for selecting blocks of text
- Command-line: for running a command
我们在此用到 insert 模式,在正常模式下按i进入 insert 模式,此时可以像其他编辑器一样对文件进行编辑,然后按ESC退回到正常模式
在正常模式下输入:会进入命令模式,最基础的命令有
:qquit (close window):wsave (“write”):wqsave and quit
事实上 vim 还有许多十分强大的功能,感兴趣的同学可以自己了解
tmux
我们在使用 ssh 方法登录到服务器的时候是和服务器进行一次会话,而当我们从服务器断开的时候,会话结束,会话中的各个进程也会被终止,而 tmux 是用来解绑会话与打开的终端窗口的,可以让你启动的进程在断开连接之后继续运行
直接输入 tmux 命令会新建一个只有编号的 tmux 窗口,我们可以这样来新建命名的窗口
$ tmux new -s <session-name>
在 tmux 窗口中,按下Ctrl+b,然后按d,可以从当前窗口分离,而窗口中的进程仍在后台运行
可以查看所有 tmux 会话
$ tmux ls
# or
$ tmux list-session
然后使用tmux attach来重新接入会话
# 使用会话编号
$ tmux attach -t 0
# 使用会话名称
$ tmux attach -t <session-name>
可以在会话中直接使用Ctrl+d或者输入exit来关闭,也可以在外部使用tmux kill-session命令杀死某个会话。
# 使用会话编号
$ tmux kill-session -t 0
# 使用会话名称
$ tmux kill-session -t <session-name>
以上为 tmux 的最基础操作,更多可以参考这里
Docker
Docker 使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核的 cgroup,namespace,以及 OverlayFS 类的 Union FS 等技术,对进程进行封装隔离,属于 操作系统层面的虚拟化技术。由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。最初实现是基于 LXC,从 0.7 版本以后开始去除 LXC,转而使用自行开发的 libcontainer,从 1.11 开始,则进一步演进为使用 runC 和 containerd。
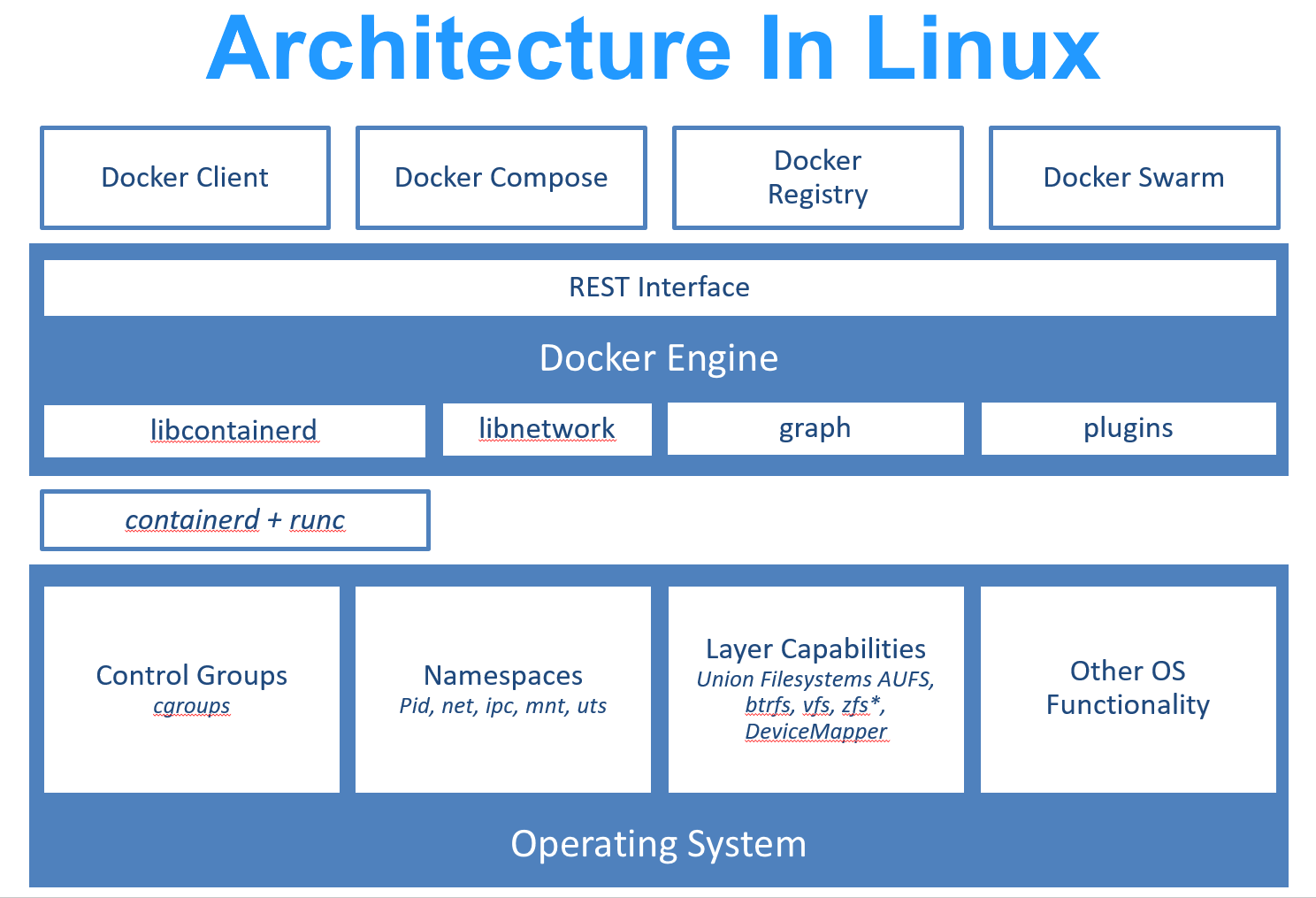
Docker 在容器的基础上,进行了进一步的封装,从文件系统、网络互联到进程隔离等等,极大的简化了容器的创建和维护。使得 Docker 技术比虚拟机技术更为轻便、快捷。
课件请见此处
参考链接
操作系统
本讲主要介绍操作系统的相关知识,帮助大家快速建立操作系统的宏观认识。需要注意的是,操作系统涉及处理机管理、存储管理、文件系统、IO设备等多个方面,而本讲主要涉及处理机管理中的进程间通信、进程的同步与互斥、死锁等内容,较少涉及其它部分。以下为本讲大纲,详细课件参见仓库。
进程与线程
进程
进程(Process)是具有独立功能的程序在某个数据集合上的一次运行活动,可以理解为操作系统执行的一个程序的实例。
三状态模型:运行、就绪、阻塞。
线程
线程(Thread)进一步减小了程序并发执行的时空开销,是轻量级进程。进程是资源分配的单位,线程是处理器调度的单位,同一个进程的多个线程共享资源。
用户级线程 vs 内核级线程
处理器
处理器状态:核心态(Kernel mode)与用户态(User mode),通过陷入(Trap)与修改程序状态字(PSW)互相切换。
CPU的一个核心上,同一时间片只能执行一个线程。操作系统在单核上实现并行的方式是通过处理器调度,使得各线程轮流执行,实现宏观并行。操作系统的调度需要陷入核心态,保存寄存器、堆栈,同时cache需要更新,因此有一定时间开销。
调度的时刻(抢先vs非抢先):
- 创建一个新进程后
- 一个进程运行完毕后
- 中断
- 一个进程被阻塞
- 时间片轮转
对于计算密集型任务,频繁调度不划算;而对于IO密集型任务,调度是有较大收益的。
原语(primitive):由若干条指令构成的 “原子操作(atomic operation)” 过程 ,作为一个整体而不可分割——要么全都完成 ,要么全都不做 要么全都不做 要么全都不做 。许多系统调用都是原语。原语可以避免因调度而被打断。
需要注意的是,C或其它编程语言的一条指令可能由多个汇编语句构成,而处理器执行汇编指令中都可能发生调度,因此同一条指令可能被打断,发生各种情况。
Linux / Windows / POSIX 中的进程与线程
Linux无线程概念,但可共享资源的进程可看作线程,相当于内核级线程。
Windows进程是惰性的,无实际作用,线程是调度单位,内核级线程。
POSIX未限定用户级/内核级线程。多线程编程接口标准pthread。
进程同步与互斥
-
禁止中断
进入临界区前执行关闭中断指令,离开临界区后执行开中断。
简单但可靠性差,不适合多处理器。
-
严格轮转法 进程严格轮流进入临界区。 忙等待,效率较低,且可能在临界区外阻塞别的进程。
-
Petersen算法 可以正常工作的解决互斥问题的算法,仍使用锁。 忙等待,效率较低。
-
硬件指令方法 使用硬件提供不被打断的单条指令读写共享变量。 适用于任意数目进程,且较简单,但仍有忙等待。
-
信号量 使用原语访问信号量管理资源。 不必忙等,效率较高,但信号量的控制分布在整个程序中,正确性难以保证。
-
管程 信号量及其操作的高级语言封装。 效率同信号量一样,易于管理开发。
-
消息传递 用以实现分布式系统的同步、互斥。 支持分布式系统,但消息传递本身效率较低且不完全可靠。
忙等待不但浪费CPU时间,还会出现优先级反转问题(priority inversion problem)。
进程间通信
Linux进程间通信
- 信号
- 管道
- 消息队列
- 共享内存
- 套接字
Windows进程间通信
- 管道
- 共享内存
- 邮件槽
- 套接字
经典IPC问题
- 生产者-消费者问题
- 读者-写者问题
- 睡眠理发师问题
- 哲学家进餐问题
死锁
死锁(Deadlock)是指系统中多个进程无限制地等待永远不会发生的条件。
死锁发生的必要条件:
- 互斥
- 请求和保持
- 非剥夺
- 环路等待
处理死锁问题的四种方法:
- 鸵鸟算法
- 死锁预防
- 预先静态分配法
- 有序资源使用法
- 死锁检测
- 资源分配图算法
- 死锁避免
- 银行家算法
C#:概述
C# 语法高度重视表达,但学习起来也很简单轻松。 任何熟悉 C、C++ 或 Java 的人都可以立即认出 C# 的大括号语法。 通常情况下,了解上述任何一种语言的开发者都可在短时间内就开始使用 C# 高效工作。 C# 语法简化了 C++ 的许多复杂操作,并提供强大功能,如可以为 null 的类型、枚举、委托、lambda 表达式和直接内存访问。
作为面向对象的语言,C# 支持封装、继承和多态性这些概念。 所有变量和方法(包括作为应用程序入口点的 Main 方法)都封装在类定义中。 虽然类可能会直接继承一个父类,但可以实现任意数量的接口。 若要用方法重写父类中的虚方法,必须使用 override 关键字,以免发生意外重定义。 在 C# 中,结构就像是轻量级类,是可以实现接口但不支持继承的堆栈分配类型。
除了这些面向对象的基本原则,使用 C# 还可以通过以下多个创新语言构造更加轻松地开发软件组件:
- 封装的方法签名(名为“委托”),可实现类型安全事件通知。
- 用作私有成员变量的访问器的属性。
- 在运行时提供有关类型的声明性元数据的特性。
- 内联的 XML 文档注释。
- 语言集成查询 (LINQ),提供跨各种数据源的内置查询功能。
C# 生成过程比 C 和 C++ 更简单,比 Java 更灵活。 没有单独的头文件,也不要求按特定顺序声明方法和类型。 C# 源文件可以定义任意数量的类、结构、接口和事件。
程序结构
一个 C# 程序主要包括以下部分:
- 命名空间声明(Namespace declaration)
- Class 类声明
- 一个 Main 方法
- 语句(Statements)& 表达式(Expressions)
- 其他方法和属性
- 一个 Main 方法
- 其他类声明
- Class 类声明
- 其他命名空间...
using System; // 在程序中包含System命名空间
namespace HelloWorldApplication // 声明命名空间
{
class HelloWorld // 声明一个类
{
static void Main(string[] args) // 静态方法
{
/* 我的第一个 C# 程序*/
HelloWorld n = new HelloWorld();
Console.WriteLine("Hello World"); // System.Console.WriteLine
/* 定义在 System 命名空间中的 Console 类的一个方法 */
Console.ReadKey(); //等待一个按键的动作
}
}
}
数据类型
值类型
- bool,char,float(1.0F),double(1.0D),short(16),int(32),long(64),uint...
- byte 8位无符号整数
- decimal:128位十进制整数/小数,有效位数28-29位(1.0M)
- 结构体(Struct)
- 传参时进行值传递,拷贝副本
- 在栈空间上分配内存,不会给垃圾回收(GC)造成负担
- 不能派生其他子类,不能使用线程锁
引用类型
-
所有类型的基类object, 字符串string,数组Array,类class,接口interfac,委托delegate..
-
传参和直接赋值时进行引用传递,可以在函数内部改变其值
-
string类较为特殊,string间赋值被重载为深复制
string s1 = "Hello, World!"; string s2 = s1; s2 = "See you!"; Console.WriteLine(s1); // "Hello, World!" Console.WriteLine(s2); // "See you!"
-
-
在堆空间上分配内存,并由GC机制进行内存管理
-
可以派生,可以使用线程锁等
指针类型
- 可以对方法添加unsafe关键字,并使用C,C++中的指针 int*等
- 在vs项目中设置允许使用不安全的代码
- 由于C#中的GC机制,一个变量(例如一个大数组)有可能在运行过程中被移动到内存中的其他位置,因此不建议使用指针类型(可以使用fixed关键字固定内存位置)
- 可以在unsafe环境中使用stackalloc分配栈内存,栈内存不受GC的影响
可空类型
- 定义变量时,在类型后添加?表示该变量可能为null:
double? num = null; - 使用变量时,在变量后添加 ?? 表示若该变量为null,则使用 ?? 后的替换值
double num2 = num ?? 1.0
类型转化
- 前加(类型名),(int)
- 调用数据对象的ToString(),ToBoolean(),ToDouble(),Toint32()方法
- 调用System空间的Convert类的相应方法
double a=Convert.ToDouble(1) - 调用VarType.Parse()方法,参数必须为string,如
Int.Parse("32") - 使用as关键字,如果转换失败则返回null,只能用于引用类型间转化
类型判断
- 使用 is 关键字
if( x is int)
装箱与拆箱
-
装箱:把值类型转换成引用类型;拆箱:把引用类型转换成值类型
-
//装箱 int i = 1; object obj = (object)i; //拆箱 int j = (int)obj; -
装箱与拆箱的过程会有性能损耗
基本语法
条件语句
- if else:同C, C++
- ?运算符:同C, C++
- switch case default:同C,C++,case需要添加break语句
循环语句
- for( init; condition; end) 语句,同C, C++
- while循环,do while循环,同C, C++
- foreach语句
- foreach(typename x in Array/Collection) //可迭代对象
- 逐一取出可迭代对象内的元素x,语句块内可以读取x的值,但不能改变x的值
String 字符串
- String类的对象,用双引号表示字符串
- 使用String类的方法多种字符串操作
- Compare, Concat, Contains, Copy, Ends/StartsWith, IndexOf, Insert, Replace, Remove, Split, Trim..
- 使用ToCharList方法转换为字符数组
- 使用@前缀表示转义字符串:
@"C:\Windows" - 使用$前缀进行字符串内插:
string name = "Mark";
var date = DateTime.Now;
Console.WriteLine($"Hello, {name}! Today is {date.DayOfWeek}.");
// Hello, Mark! Today is Wednesday.
- 也可使用Format方法插入数值,但较为繁琐
Console.WriteLine("Hello, {0}! Today is {1}.", name, date.DayOfWeek);
Array 数组
double[] a = new double[10];double[] b = a;//a和b指向同一内存位置double[] a = { 2340.0, 4523.69, 3421.0};- 数组作为参数传入时,函数体内可修改数组元素的值
多维数组
-
类似矩阵的数据结构
int [,] a = new int [2,3] { {0, 1, 2} , {3, 4, 5} , }; -
访问元素:
int b = a[1,2] \\5 -
使用Rank属性获取多维数组的维数,使用GetLength(d)来获取第d维的长度
-
foreach循环会遍历每个元素
交错数组
- 类似C,C++中的多维数组,本质是“元素是数组的数组"
int[][] a = new int[2][]{new int[]{92,93,94},new int[]{85,66,87,88}};- 获取a的Rank属性,得到结果为1,foreach循环只会遍历各个数组
Struct 结构体
- 可以定义字段,属性(区别一会儿再说),方法,构造函数,不能定义析构函数
- 可以声明静态成员
- 构造函数必须带参数,且在构造函数中必须为每个字段赋值
- 作为参数时是值传递,储存在栈空间中,所需空间较小
- 不能继承和派生
struct Books
{
private string title;
private string author;
public Books(string t, string a)
{
title = t;
author = a;
}
};
Enum 枚举
- 同C, C++,默认为Public,可以显式指定枚举对应的值
enum Numbers
{
One,
Three = 3,
Four // 从上一项的值+1
}
static void Main()
{
Numbers num = Numbers.Three;
Console.WriteLine(num); // "Three"
int one = 1;
num = (Numbers) one; // Enum和int可以强制类型转换
Console.WriteLine(Convert.ToString(num)); // 使用Convert获取枚举字符串
string four = "Four";
num = (Numbers)Enum.Parse(typeof(Numbers), four); //由字符串转换为枚举
Console.WriteLine((int)num);
}
Class 类
- 基本定义同C,C++,有构造和析构函数(不支持构造函数的简洁写法)
- 作为参数时是引用传递
- 静态变量和静态方法:该类的各个对象共享同一个变量,而静态方法只能使用静态变量,调用静态方法
- main方法是静态方法,故Program类中的全局变量应该设为静态变量
- 可以使用类名.方法名,不实例化类的对象直接调用静态方法
方法
- 在类中定义方法,每一个 C# 程序至少有一个带有 Main 方法的类。
public int Max(int ref num1, int ref num2)
{
return num1 > num2 ? num1 : num2;
}
-
使用非静态方法时必须先实例化类的对象,如在Program类中声明了main函数和以上Max函数,则在main函数中调用Max函数时,需先声明Program对象:
Program n = new Program();,再调用相应的方法:n.Max(ref a, ref b) -
参数传递:
- 值传递:拷贝值型变量的副本
- 引用参数:在方法的参数列表和调用方法时均增加ref关键字
- 输出参数:在方法的参数列表和调用方法时均增加out关键字, out参数必须在方法内赋值,且不能在赋值前被使用
访问控制
- public, private, protected(对该类对象及其子类对象可以访问)
- 如果不声明,则默认为private
继承与派生
- 继承和派生与C,C++类似,继承后子类可以访问父类中public和protected的字段,属性和方法
| 实方法 | 虚方法 | 抽象方法 | |
|---|---|---|---|
| 修饰符 | / | virtual | abstract |
| 父类要求 | / | / | 有抽象方法的类也为抽象类 |
| 父类实现 | / | 父类必须给出虚方法的实现 | 父类可以只声明抽象方法 |
| 子类实现 | 子类可以覆盖实方法 | 子类可以重载或覆盖虚方法 | 子类必须重载虚方法 |
| 重载(override) | × | √ | √ |
| 覆盖(new) | √ | √ | × |
| 基类调用(base) | √ | √ | √ |
| 密封类(sealed) | √ | √ | × |
- 覆盖与重载的区别:覆盖后子类的实例可以调用父类被覆盖的方法(强制类型转换),而重载后则不可以,对于虚方法一般使用重载
- 声明密封类:此类不能被继承
using System;
namespace CSharpLearning
{
abstract class Animal // 有抽象方法的类必须是抽象类
{
public Animal(){};
public void Move() // 实方法
{
Console.WriteLine("调用了Animal类的Move方法");
}
public virtual void Attack() // 虚方法,必须给出实现
{
Console.WriteLine("调用了Animal类的Attack方法");
}
public abstract void Name(); // 抽象方法,可以只声明,不实现
}
sealed class Cat : Animal // 密封类,不能派生,继承了Animal类
{
public override void Name() // 若不重载抽象方法则会报错
{
Console.WriteLine("调用了Cat类的Name方法");
}
public override void Attack() // 可以重载父类的虚方法,也可不重载,还可用new覆盖父类的虚方法
{
Console.WriteLine("调用了Cat类的Attack方法");
}
public new void Move() // 使用new覆盖父类的实方法
{
base.Move(); // 使用base关键字调用父类的同名方法
Console.WriteLine("调用了Cat类的Move方法");
}
}
class Program
{
static void Main(string[] args)
{
// Animal animal = new Animal(); 报错:无法创建抽象类Animal的实例
Cat cat=new Cat();
cat.Name(); // 调用了Cat类的Name方法
cat.Move(); // 调用了Animal类的Move方法/n 调用了Cat类的Move方法
((Animal)cat).Move(); // 调用了Animal类的Move方法
((Animal)cat).Attack(); // 调用了Cat类的Attack方法
Console.ReadKey();
}
}
}
字段与属性
- 更多参考资料
- 字段又称“成员变量”,一般在类的内部做数据交互使用,命名时通常首字母小写
- 属性是外界访问私有字段的入口,负责指定相应字段的读、写方式,命名与对应字段相同且首字母大写
- 声明属性时,首先声明相应的私有字段,然后指定属性的get和set访问器
class Person
{
private int age;
public int Age
{
get { return age; }
set { age = value > 120 ? 120 : value; }
// 此处value为关键字,代表用户所赋的值
}
}
- 在C# 7.0之后也可用类似lambda表达式的方法设置属性
class Person
{
private int age;
public int Age { get => age; set => age = value > 120 ? 120 : value; }
// 注意set语句中仍需对age赋值
// 如果只实现get访问器,则可以进一步简化为 public int Age => age;
}
- 使用属性对应字段的值时,直接对属性读取或赋值:
Person person = new Person();
person.Age = 20;
Console.WriteLine(person.Age);
-
若属性访问器中不需要任何其他逻辑时,我们可以使用自动实现的属性,不需要声明相应字段
public int Age { get; set; } -
此时也可进行初始化
public string Name { get; set; } = "Jane"; -
若去除set访问器,则属性变为只读的,必须为其指定初始值
public string Name { get; } = "Jane";
运算符重载
- 基本与C,C++一致,使用operator关键字且应声明为static方法
public static Student operator +(Student s1, Student s2)
{
return new Student(s1.age + s2.age, s1.name + " And " + s2.name);
}
- 重载 == 操作符后也必须重载 != 操作符
- 重载 + 操作符后 += 操作符也自动被重载,- , * , / 等类似
- 使用Implict/Explict关键字重载隐式/显式类型转换运算符
public static implict operator A(B b)类型B到类型A的隐式转换
Interface 接口
- 接口使用 interface 关键字声明,它与类的声明类似。接口声明默认是 public 的
- 抽象类在某种程度上与接口类似,但是,抽象类大多用于只有少数方法由基类声明而由派生类实现时,接口则指定的其派生类应遵循的标准
- 接口通常以大写 I 开头命名,接口的定义与类的定义相似(interface关键字),其中方法默认为public,接口内也可有属性的声明,但不能有字段
- C#中不允许继承多个类,但可以继承多个接口
- 接口可以继承其他接口,而实现该接口的类应该实现所有接口的方法和属性
interface IPerson
{
string Name { get; set; }`
void Show(string name);
}
interface IStudent //也可继承IPerson接口,则Student类只需继承IStudent接口
{
string Id { get; set; }`
void Show(string id); //若继承IPerson接口,则应加new修饰符覆盖同名方法
}
class Student: IPerson, IStudent //多继承
{
public string Name { get; set; }`
public string Id { get; set; }`
void IPerson.Show(string name) //分别实现不同接口的同名方法
{
Console.WriteLine("姓名为{0}", name);
}
void IStudent.Show(string id) //如果指定实现接口的函数,则可以不使用访问控制
{
Console.WriteLine("学号为{0}", id);
}
//public void Show(string id) //如果统一实现,则必须指定访问控制符
//{
// Console.WriteLine("姓名为{name},学号为{id}");
//}
}
class Program
{
static void Main()
{
Student s = new Student();
Console.WriteLine("输入姓名");
s.Name = Console.ReadLine();
Console.WriteLine("输入学号");
s.Id = Console.ReadLine();
IPerson per = s;
per.Show(s.Name);
IStudent stu = s;
stu.Show(s.Id);
}
}
- 函数可以使用接口作为参数,在传参时传入不同实现该接口的类的实例
Exception 异常处理
- 类似C++的 try - throw - catch - finally结构
- 一个try块至少对应一个catch块或1个finally块
- 只会进入从上向下的第一个匹配的代码块,若当前函数中没有匹配的catch块则会搜索外层函数
static int GetInt(int[] array, int index)
{
try
{
return array[index];
}
catch (System.IndexOutOfRangeException ex) //下标越界的更具体原因在于传递了越界的参数index
{
Console.WriteLine(ex.Message);
// 创建更精确的异常并抛出给外层函数
throw new ArgumentException("index parameter is out of range.", "index", ex);
}
}
static void Main()
{
try
{
int[] a = {1, 2, 3, 4, 5};
GetInt(a, 5);
}
catch (ArgumentException ex)
{
Console.WriteLine(ex.Message);
}
catch (Exception)
{
Console.WriteLine("发生未知错误!");
}
finally //一般用于释放资源
{
Console.WriteLine("Done!");
}
}
Delegate 委托
- 类似于C, C++的函数指针,可用于引用任何返回值和参数列表相同的方法
- delegate void printString(string s);`
- 声明委托后,使用new创建委托对象,并且传入要引用的函数名作为参数
printString ps1 = new printString(WriteToScreen);
- 此后可以使用委托对象调用对应
多播委托
- 作用于参数和返回值相同的委托对象直接
- 委托类型重载了 + - 运算符,可用于依次执行一系列任务,再返回值
using System;
namespace Program
{
delegate int NumberChanger(int n); // 委托可以直接在命名空间内声明
class TestDelegate
{
public static int Num { get; set; } = 10;
public static int AddNum(int p)
{
Num += p;
return Num;
}
public static int MulNum(int q)
{
Num *= q;
return Num;
}
static void Main(string[] args)
{
NumChanger fc1 = new NumChanger(AddNum);
NumChanger fc2 = new NumChanger(MulNum);
NumChanger fc = fc2 + fc1;
Console.WriteLine(fc(5)); // 75 = (10 * 5) + 5
}
}
}
- 委托可以接受匿名函数作为参数
NumChanger fc1 = delegate(int p) { Num += p; return p;};
- 也可以接受一个lambda表达式作为参数:
NumChanger fc1 = (int p) => { Num += p; return p;};
lambda表达式
- 表达式lambda,自动返回表达式的值
- (int x, int y) => x * y 或省略类型声明 (x, y) => x * y
- 只有1个参数时可省略左侧的括号 x => x * x * x
- 语句lambda
- (int x, int y) => { return x * y; }
- 右侧用大括号扩起,内部可以有多条语句(不宜过多),也可没有返回值
Generic 泛型
- 类似C++ 的模板,可以兼容不同的数据类型,但限制更多
- 泛型类:
class MyArray<T> - 泛型方法:
static void Swap<T>(ref T x, ref T y) - 泛型委托:
delegate T NumberChanger<T>(T n); - 泛型接口:
interface IDictionary<K, V> - 继承泛型类或接口时待定类型只能不变或增多
泛型的类型约束
-
声明泛型时可以给泛型添加一定的约束:
class MyArray<T> where T : struct -
where T : struct :T必须为(不可为空的)值类型
-
where T : class :T必须为(不可为空的)引用类型
-
where T : notnull :T必须为不可为空的类型
-
where T : new() :T必须具有无参数的构造函数,不能与struct合用
-
where T : <interface name> :T必须实现指定的接口
-
where T : <base class name> :T必须为指定类或其派生类
-
多个限制并用:用逗号分隔
-
约束多个参数:
class Base { } class Test<T, U> where U : struct where T : Base, new()
Collections 集合
- 包含了一系列基本数据结构的命名空间
- ArrayList, SortedList, Hashtable, Stack, Queue..
- 一般包含Add, Clear, Remove等方法
- 包含一些基本的接口,如 IComparer, IEnumerator(迭代), IList(按索引访问)
- 并未指定成员的数据类型,因此全部成员都被转换为object类
- 对于值类型,使用Collections意味着频繁的装箱和拆箱,性能不佳
Collections.Generic
- 利用泛型值类数据类型的数据结构,拥有更好的类型安全性和性能
- Tuple<T1, T2, T3, ...> ,使用.Item1, .Item2来访问,类似C++的pair
- 使用C# 7.0的新特性元组实现此功能
- (1, 2); ("one", "two"),...
- 可以为每个元组的元素起别名:(x : 1, y : 2)
- 元组支持直接赋值和比较
- List<T> 类似C++ vector
- Dictionary<T1, T2>
- Queue<T>, Stack<T>
- HashSet<T>
常用库函数介绍(补充)
-
System.IO 包含对一系列系统调用的支持,比如各种文件操作
- FileStream
- StreamReader 与 StreamWriter 进行文本文件读写
- BinaryReader 和 BinaryWriter 类用于二进制文件的读写
- DirectoryInfo 类和 FileInfo 类用于进行windows文件系统的操作
-
System.Linq 使用一定格式的语句查询和筛选可迭代对象
-
System.Text 包含一系列编解码相关的功能
-
System.Text.RegularExpressions; 包含正则表达式的基类Regex
-
System.Threading 提供启用多线程的类和接口.
-
事件、异步、多线程... 未完待续
C#课程2(事件、异步、多线程)
一、事件(event)
通俗来讲,事件是一种广播机制
比如某个组件订阅了一个事件,那么在这个事件被触发的时候组件会收到通知。
例:小明家里有一部电话,有一个正在烧水的热水壶,电话响了(这是一个event)就会触发小明接电话(这是一个方法)这个动作。(*注:这部分代码参考Event.cs)
事件可以实现底层程序集调用高层程序集的方法。并且在调用的时候可以向高层程序集的方法传入参数。
例:我写了一个库,这个库给出一个Read的事件,这个事件会在控制台输入字符串的时候被调用。(*注:这部分代码参考Event2.cs)
二、多线程
1. 简介
进程是操作系统执行程序的基本单位
一个进程拥有多个线程,这些线程之间资源共享。
使用线程进行并发式编程。
C#提供了完整的多线程库
2. 常用方法
以下代码显示了如何创建一个线程
using System.Threading; // 包含多线程需要的库
public static void Function() // 一个需要被线程调用的函数
{
Console.WriteLine("Function !");
}
Thread t = new Thread(Function); // 用Function函数初始化线程
上面的代码并没有让线程运行,如果要让线程开始运行,需要调用 Start() 方法。
t.Start();
如果Function的定义修改为如下
public static void Function(string str);
那么在Start()方法中就要传入参数。
t.Start("Hello World");
使用Sleep()方法可以暂停线程一段时间,单位为毫秒。
Thread.Sleep(1000) // 线程停顿1秒
使用Join()方法可以阻塞当前线程,等待某一个线程执行完毕后再进行后面的任务。比如下面的代码,展示了Join()方法的阻塞作用
public static void Function()
{
for (int i = 0; i < 10; i++)
{
Thread.Sleep(200);
Console.WriteLine("Function !");
}
}
public static void Run()
{
Thread t = new Thread(Function);
t.Start();
Thread.Sleep(500);
t.Join(); // 这里阻塞了Run()方法所在线程,等待t执行完毕
Console.WriteLine("Finish !");
}
注意!非常不建议使用Suspend()、Abort()等方法在线程外部暂停或终止一个线程。
3. 常用属性
- IsBackground 属性,显示一个线程是否为后台线程。
- 如果一个线程为后台线程,那么程序不会等待这个线程执行完毕;如果一个线程是前台线程,程序会等待线程执行完毕再退出。
- IsAlive 属性,显示一个线程是否正在运行。
- IsThreadPoolThread 属性,显示线程是否属于托管线程池。
下面的代码展示了如何控制一个线程是否为后台线程
new Thread(() =>
{
for (int i = 0; i < 10; i++)
{
Thread.Sleep(300);
Console.WriteLine("Thread1 : " + i);
}
})
{ IsBackground = true }.Start();
new Thread(() =>
{
for (int i = 0; i < 6; i++)
{
Thread.Sleep(300);
Console.WriteLine("Thread2 : " + i);
}
})
{ IsBackground = false }.Start();
三、异步编程
1. 简介
C# 引入了async和await关键字后,异步编程变得十分方便
实际上异步编程也是多线程的一种,只不过不需要手动创建线程,线程从线程池中被创建
例:比如我们在处理UI和按钮单击时,需要运行一个长时间运行的方法,比如读取一个大文件,如果采用同步编程,整个程序必须等待这个任务完成才能执行其他任务。
2. Task介绍
使用Task可以很方便地创建一个任务并运行,下面的代码展示了如何创建任务。
Task.Run(Method1);
还可以采用其他形式创建任务
Task task = new Task(Method1);
task.Start();
还可以采用Factory创建并运行任务
Task.Factory.StartNew(Method1);
Task的生命周期:Task.Status
Task的生命周期有如下几种状态:
- Created : 已经被创建但还未开始运行
- Running : 正在运行
- RanToCompletion : 执行完毕
下面的代码展示了Task的生命周期:
public static void Method1()
{
for (int i = 0; i < 5; i++)
{
Thread.Sleep(200);
Console.WriteLine("Method1 : " + i);
}
}
public static void Run()
{
Task task = new Task(Method1);
Console.WriteLine(task.Status);
task.Start();
for (int i = 0; i < 7; i++)
{
Thread.Sleep(200);
Console.WriteLine(task.Status);
}
}
输出结果如下:
Created
Running
Method1 : 0
Method1 : 1
Running
Running
Method1 : 2
Method1 : 3
Running
Running
Method1 : 4
RanToCompletion
RanToCompletion
Task的任务控制,可以控制多个Task的执行顺序
Task.Wait()方法等待任务执行完毕
Task task1 = new Task(Method1);
task1.Start();
task.Wait(); // 等待任务执行完毕
Console.WriteLine("task Finish");
Task.WaitAll()等待所有任务执行完毕
Task task1 = new Task(Method1);
task1.Start();
Task task2 = new Task(Method2);
task2.Start();
Task.WaitAll(task1, task2);
Console.WriteLine("task Finish");
Task.WaitAny() 等待任一任务执行完毕
Task task1 = new Task(Method1);
task1.Start();
Task task2 = new Task(Method2);
task2.Start();
Task.WaitAny(task1, task2);
Console.WriteLine("task Finish");
Task 返回值 Task< TResult >
任何一个异步Task都可以返回一个值,下面的代码展示了如何获取Task的返回值。
public static string MethodReturn()
{
for (int i = 0; i < 5; i++)
{
Thread.Sleep(200);
Console.WriteLine("MethodReturn : " + i);
}
return "MethodReturn finish";
}
Task<string> taskReturn = new Task<string>(MethodReturn);
taskReturn.Start();
Console.WriteLine("Task finish with : " + taskReturn.Result);
可以看到只需要调用Task.Result就可以获取Task的返回值,并且在尝试获得Task的返回值时会自动阻塞当前线程,直到Task结束。
3. async 和 await
await 和字面意思一样,就是等待,下面的代码展示了等待一个任务执行完毕
public static async void Run()
{
await Task.Run(Method1);
Console.WriteLine("Task1 finish ");
}
await 更大的用处是等待一个有返回值的Task,如下代码所示:
public static async void Run()
{
Task<string> task = new Task<string>(MethodReturn);
task.Start();
Console.WriteLine("Task1 finish with : " + await task);
}
async 的意思也和字面意思完全一样,就是表明一个方法是异步方法,下面展示了一个异步方法:
public static async void TestAsync()
{
await Task.Run(
() =>
{
for (int i = 0; i < 5; i++)
{
Thread.Sleep(200);
Console.WriteLine("TestAsync : " + i);
}
});
}
public static async void Run()
{
TestAsync();
Console.WriteLine("Task1 finish ");
}
可以注意到凡是方法体里出现了await关键字的,方法定义必然要出现async关键字,这是显然的,因为凡是有await关键字的方法必为异步方法。
需要注意的是如果一个被async修饰的方法里面没有await关键字的话,那么这个方法和同步方法没有区别。
一个async方法里面的异步操作仅出现在await关键字之后。
public static async void TestAsync()
{
for (int i = 0; i < 3; i++)
{
Thread.Sleep(200);
Console.WriteLine("Sync : " + i);
}
await Task.Run(
() =>
{
for (int i = 0; i < 5; i++)
{
Thread.Sleep(200);
Console.WriteLine("TestAsync : " + i);
}
});
}
public static async void Run()
{
TestAsync();
Console.WriteLine("Task1 finish ");
}
因为async方法为异步方法,所以调用async方法的时候常常也使用await。
public static async Task<string> AsyncReturn()
{
await Task.Run(
() =>
{
for (int i = 0; i < 5; i++)
{
Thread.Sleep(200);
Console.WriteLine("AsyncReturn : " + i);
}
});
return "AsyncReturn finish";
}
public static async void Run()
{
var str = await AsyncReturn();
Console.WriteLine("Task1 finish with : " + str);
}
注意:async方法的返回值只能为void、Task、Task< TResult >,不能为其他
四、锁
多线程编程过程中常常会出现多个线程同时访问一个资源的情况,这个时候就需要用到锁,把共享的资源锁起来。
一个不使用锁的例子:
int num = 0;
Task.Run(
() =>
{
for (int i = 0; i < 1000; i++)
{
num++;
}
Console.WriteLine("Thread 1 : " + num);
}
);
Task.Run(
() =>
{
for (int i = 0; i < 1000; i++)
{
num++;
}
Console.WriteLine("Thread 2 : " + num);
}
);
锁的使用非常简单,只需要使用 lock 关键字就可以锁住一个对象,一个对象同时只允许一个线程访问,其他线程在这个期间会被阻塞。
int num = 0;
object numlock = new object();
Task.Run(
() =>
{
for (int i = 0; i < 1000; i++)
{
lock (numlock)
num++;
}
lock (numlock)
Console.WriteLine("Thread 1 : " + num);
}
);
Task.Run(
() =>
{
for (int i = 0; i < 1000; i++)
{
lock (numlock)
num++;
}
lock (numlock)
Console.WriteLine("Thread 2 : " + num);
}
);
下面这段代码展示了锁是如何阻塞线程的:
object tasklock = new object();
Task.Run(() =>
{
lock (tasklock)
for (int i = 0; i < 5; i++)
{
Thread.Sleep(200);
Console.WriteLine("Thread 1");
}
}
);
Task.Run(() =>
{
lock (tasklock)
for (int i = 0; i < 5; i++)
{
Thread.Sleep(200);
Console.WriteLine("Thread 2");
}
}
);
除了使用 lock 关键字,还可以使用 Moniter 来锁定和释放对象。
Monitor.Enter(objlock);
Monitor.Exit(objlock);
注意:
- 应避免锁定 public 对象,否则实例将超出代码的控制范围。
- 锁定对象应当为 readonly 以免在锁定的过程中发生改变
- 不能锁定值类型
lock(9) // 错误,不能锁定值类型
lock(this) // 错误,违反了不能锁定 public 对象的规范
lock("Hello World") // 错误,相同字符串同一程序中只有一个实例对象,相当于锁定 public 对象。
下面是正确示例
private static readonly object objlock = new object();
lock(objlock)
...
读写锁
允许多个线程同时获取读锁,但同一时间只允许一个线程获得写锁
当某个线程进入读取模式时,此时其他线程依然能进入读取模式,假设此时一个线程要进入写入模式,那么他不得不被阻塞。
如果某个线程进入了写入模式,那么其他线程无论是要写入还是读取,都是会被阻塞的。
ReaderWriterLockSlim rw = new ReaderWriterLockSlim();
int num = 5;
for (int i = 0; i < 5; i++)
{
int tmp = i;
Task.Run(() =>
{
rw.EnterReadLock();
for (int j = 0; j < 5; j++)
{
Thread.Sleep(200);
Console.WriteLine("Thread " + tmp + " is reading");
}
rw.ExitReadLock();
});
}
上面的代码展示了多个线程可以同时获取读锁。
ReaderWriterLockSlim rw = new ReaderWriterLockSlim();
int num = 5;
for (int i = 0; i < 5; i++)
{
int tmp = i;
Task.Run(() =>
{
for (int j = 0; j < 5; j++)
{
rw.EnterReadLock();
Thread.Sleep(200);
Console.WriteLine("Thread " + tmp + " is reading");
rw.ExitReadLock();
}
});
}
Thread.Sleep(400);
Task.Run(() =>
{
rw.EnterWriteLock();
for (int j = 0; j < 5; j++)
{
Thread.Sleep(200);
Console.WriteLine("Thread is writing");
}
rw.ExitWriteLock();
});
上面的代码展示了当一个线程获取写锁的时候其他线程都被阻塞。
死锁的产生
考虑下面的程序运行过程:
Thread1 : lock 1 -> attempt to lock 2
Thread2 : lock 2 -> attempt to lock 1
这是一个最简单的死锁例子。两个线程都无法继续运行下去,程序产生了死锁。
object lock1 = new object();
object lock2 = new object();
Task.Run(() =>
{
lock (lock1)
{
Console.WriteLine("Thread 1 has lock 1");
Thread.Sleep(1);
Console.WriteLine("Thread 1 attempt to lock 2");
lock (lock2)
{
Console.WriteLine("Thread 1 has lock 2");
}
}
});
Task.Run(() =>
{
lock (lock2)
{
Console.WriteLine("Thread 2 has lock 2");
Thread.Sleep(1);
Console.WriteLine("Thread 2 attempt to lock 1");
lock (lock1)
{
Console.WriteLine("Thread 2 has lock 1");
}
}
});
哲学家就餐问题
有五个哲学家,他们的生活方式是交替地进行思考和进餐。他们共用一张圆桌,分别坐在五张椅子上。
在圆桌上有五个碗和五支筷子,平时哲学家进行思考,饥饿时便试图取用其左、右最靠近他的筷子,只有在他拿到两支筷子时才能进餐。进餐完毕,放下筷子又继续思考。
死锁的产生:五位哲学家同时饥饿而各自拿起了左边的筷子,当他们试图去拿起右边的筷子时,都将因无筷子而无限期地等待下去。
死锁产生的条件
- 互斥条件。即某个资源在一段时间内只能由一个进程占有
- 不可抢占条件。进程所获得的资源在未使用完毕之前,资源申请者不能强行地从资源占有者手中夺取资源
- 占有且申请条件。进程至少已经占有一个资源,但又申请新的资源
- 循环等待条件。存在一个进程等待序列{P1,P2,...,Pn},其中P1等待P2所占有的某一资源,P2等待P3所占有的某一源,......
死锁的解决
- 打破互斥条件,允许进程同时访问某些资源(废话)
- 打破不可抢占条件,即允许进程强行从占有者那里夺取某些资源(也是废话)
- 打破占有且申请条件。可以实行资源预先分配策略。即进程在运行前一次性地向系统申请它所需要的全部资源(很难满足条件)
- 资源编号,线程在申请资源时,必须按顺序申请(实现简单,常用)
- 银行家算法(有一定的限制条件)
资源编号策略:
- 1 号哲学家拿起 1 号筷子
- 2 号哲学家拿起 2 号筷子
- 3 号哲学家拿起 3 号筷子
- 4 号哲学家拿起 4 号筷子
- 5 号哲学家拿起 ? 号筷子
“避免死锁的最好办法,就是不要用锁。” 著名哲学家沃尔兹基说。
五、原子操作
就如其字面意思,原子操作就是计算机中不可再分割的操作。
C# 提供了一个原子操作库 Interlocked ,可以使用 Interlocked 把常见的操作转化为原子操作。
常见的操作有 i++ (自增操作),如果使用 lock 则系统开销过大,不值得使用,可以使用原子操作进行改写。
int num = 0;
Task.Run(
() =>
{
for (int i = 0; i < 1000; i++)
{
Interlocked.Increment(ref num);
}
Console.WriteLine("Thread 1 : " + num);
}
);
Task.Run(
() =>
{
for (int i = 0; i < 1000; i++)
{
Interlocked.Increment(ref num);
}
Console.WriteLine("Thread 2 : " + num);
}
);
除了 Increment 之外,还有许多其他原子操作,比如:
Add(ref T a, T b); // a = a + b
Exchange(ref T a, T b); // a = b
CompareExchange(ref T a, T b, int c); // if(b == c) a = b;
Decrement(ref T a); // a--
六、C# 并发集合
C# 默认的集合并不是线程安全的,当多个线程同时对一个集合作修改时可能会发生异常:
List<int> l = new List<int>();
Task.Run(() =>
{
for (int i = 0; i < 10000; i++)
{
l.Add(i);
}
Thread.Sleep(10);
Console.WriteLine(l.Count);
});
Task.Run(() =>
{
for (int i = 0; i < 10000; i++)
{
l.Add(i);
}
Thread.Sleep(10);
Console.WriteLine(l.Count);
});
C# 提供了多个线程安全集合类,这些线程安全集合都是无锁的,能够支持高效的多线程操作
下面以 ConcurrentQueue< T > 为例展示一下线程安全集合类的用法:
ConcurrentQueue<int> q = new ConcurrentQueue<int>(); // 新建一个线程安全队列。
q.Enqueue(9); // 数字 9 入队
q.TryDequeue(out int temp); // 从队列头取出一个数
Console.WriteLine(temp);
注意,Concurrent 集合通常都有 Try 方法,凡是 Try 方法都不一定能执行成功,并且都会返回一个布尔值,用来显示 Try 方法是否执行成功。
Concurrent 命名空间下没有 HashSet< T > 的对应线程安全集合,但可以用 ConcurrentDictionry< T, byte > 来代替。
除了 Concurrent 命名空间下的集合,C# 还提供了 BlockingCollection 阻塞集合。这个集合的特点是当集合为空时,想要从集合里取出元素会被阻塞
BlockingCollection<int> b = new BlockingCollection<int>();
Task.Run(() =>
{
for (int i = 0; i < 10; i++)
{
Thread.Sleep(300);
b.Add(i);
Console.WriteLine("Add " + i);
}
});
Task.Run(() =>
{
for (int i = 0; i < 10; i++)
{
Console.WriteLine("Take " + b.Take());
}
});
上面这段代码展示了 BlockingCollection 是如何把线程阻塞的。
利用 BlockingCollection 可以实现事件队列,强制把所有事件放在同一线程里执行。
BlockingCollection<Action> EventQueue = new BlockingCollection<Action>();
new Thread(() =>
{
while (true)
EventQueue.Take()();
}).Start();
只需要很少的代码就可以实现事件队列的编写。
我们可以用如下代码测试事件队列:
for (int i = 0; i < 10; i++)
{
Thread.Sleep(300);
Task.Run(() =>
{
EventQueue.Add(() =>
{
Console.WriteLine(DateTime.Now);
});
});
}
七、C#定时器
C# 里提供了几种定时器的实现方法。
System.Threading.Timer
下面的代码展示了如何新建一个定时器
System.Threading.Timer timer = new Timer(
(o) =>
{
Console.WriteLine("Timer !");
}, null, 1000, 200);
Timer() 的构造方法第一个参数为定时执行的回调函数,第二个参数为传递给回调的参数,第三个参数为 duetime ,即在开始计时前等待多长时间,第四个参数为 period ,即定时器周期。
也可以采用如下代码开始一个定时器:
System.Threading.Timer timer = new Timer(
(o) =>
{
Console.WriteLine("Timer !");
});
timer.Change(1000, 200);
上面的定时器在构造时并没有开始运行,在调用 Change() 方法后才开始运行。
System.Threading.Timer 在运行过程中随时可以调用 Change() 方法改变定时器的周期。
System.Timers.Timer
System.Timers.Timer 是比 System.Threading.Timer 更加灵活的一种定时器。
下面的代码展示了如何使用 System.Timers.Timer
System.Timers.Timer timer = new System.Timers.Timer();
timer.Elapsed += (o, e) =>
{
Console.WriteLine("Timer !");
};
timer.Interval = 300;
timer.Enabled = true;
timer.Elapsed 是一个 event ,每个周期都会被调用。
注意: System.Timers.Timer 比 System.Threading.Timer 更加灵活的地方就在于 Elapsed ,你可以在不重新 new 定时器的情况下改变定时器的回调函数。
public static void CallBack(Object o, System.Timers.ElapsedEventArgs e)
{
Console.WriteLine("Timer !");
}
System.Timers.Timer timer = new System.Timers.Timer();
timer.Elapsed += CallBack;
timer.Interval = 300;
timer.Enabled = true;
Thread.Sleep(1200);
timer.Elapsed -= CallBack; // 这里把 CallBack 函数剥离 Elapsed
System.Timers.Timer 的一些属性:
bool Enabled; // 定时器是否正在运行
bool AutoReset; // 定时器是否周期执行,若为false,则表明定时器只执行一次。
int Interval; // 定时器执行的周期
八、C# 线程池
线程池的作用是避免重复创建和销毁线程。
程序里常常会创建大量线程,但这些线程只使用了一小段时间就被挂起或进入休眠,一直等到程序结束都不会再使用。
C# 提供了线程池用于线程复用,当一个异步方法想要调用线程来运行,可以先到线程池里看看有没有空闲线程
如果有空闲线程则调用空闲线程完成任务。
ThreadPool.QueueUserWorkItem(
(o) =>
{
for (int i = 0; i < 5; i++)
{
Thread.Sleep(300);
Console.WriteLine("Thread Pool !");
}
}
);
调用线程池非常简单,只要像上面这段代码一样把一个 Callback 塞进线程就行。
线程池在创建之初会有一个最小线程数,这与计算机的 CPU 核心数有关,可以用 ThreadPool.GetMinThreads() 方法获取。
ThreadPool.GetMinThreads(out int workerThreads, out int IOThreads);
Console.WriteLine(workerThreads + " " + IOThreads);
需要注意的是,Task 和 Timer 也是默认调用线程池里的线程来完成工作的。
如果线程池中的线程被用完了怎么办呢?这个时候系统会停顿 1 秒钟,观察线程池中其他线程是否执行完毕,如果有线程执行完毕的话则调用这个线程,如果没有的话则对线程池进行扩容,增加一个线程。
for (int i = 0; i < 12; i++)
{
int tmp = i;
Task.Run(() =>
{
Console.WriteLine("Thread " + tmp);
Console.ReadKey();
});
}
上面这段代码展示了线程池是如何进行扩容的。
我们可以用 SetMinThreads() 方法设置线程池的最小线程数
ThreadPool.SetMinThreads(16, 16);
设置了最小线程数后再执行上面的代码则不会出现新的任务要等待 1 秒的情况
我们也可以用 SetMaxThreads() 方法设置线程池的最小线程数
ThreadPool.SetMaxThreads(8, 8);
像这样设置了线程池的最大线程数后,上面的代码中 Thread 8 ~ 11 则永远不会被执行,因为 Thread 8 ~ 11 要等到线程池有空闲时才能执行。
线程池的其他方法:
ThreadPool.GetAvailableThreads(out int workerThreads, out int completionPortThreads); // 获取线程池中的空闲线程。
ThreadPool.ThreadCount; // 获取线程池中的线程数目
Unity3D基础
Unity简介
Unity是一款由Unity Technoligies开发的跨平台2D/3D游戏引擎,并可以发布到Windows, MacOS, Linux, iOS等诸多平台。
Unity官网:https://unity.com/
Unity官方学习资源:https://learn.unity.com/
Unity官方文档:https://docs.unity3d.com/Manual/index.html
Google/Unity Forums
Unity开发环境
Unity工程及Unity Editor版本管理:Unity Hub
图形化编辑界面:Unity Editor
下载地址:https://unity3d.com/get-unity/download
需要注册Unity账号。非盈利的个人开发者免费使用。
代码编辑器:Visual Studio(安装时选择"使用Unity的游戏开发"),VS Code(在Unity Editor中修改默认代码编辑器),其他。
Unity基本知识
Scene(场景)
Scene包含了若干GameObject,一个游戏可以包含多个场景,不同的场景之间是独立的,并且可以通过脚本切换场景。
GameObject(游戏对象)
一个GameObject就是场景中的一个对象,比如一个球,一个人;它可以独立地活动。GameObject之间存在Parent和Children的关系,即一个对象可以从属于另一个对象,成为其子对象。
请注意,GameObject之间的父子关系并非继承关系,而只是一种从属关系。
Component(组件)
一个GameObject可以拥有若干个Component,两者之间仍是一种从属关系。每个Component可以独立地实现GameObject需求的某些功能。常用的如Rigid(刚体),Animator(动画)等。
Prefab(预设)
Prefab与GameObject之间的关系类似于类和对象的关系。即后者是前者的实例。Prefab的使用能够减少不必要的重复工作。当Prefab被修改时,它的所有GameObject实例也会被修改。
Script(脚本)
通过编写代码,并将Script添加为某个GameObject的Component,当该GameObject被实例化并且处于活动状态,且该Component也处于活动状态时,它便可以控制GameObject的行为。
Unity脚本是基于Mono的,所有需要使用Unity引擎的脚本,都应该继承自MonoBehaviour类。换句话说,只有那些完全不依赖于Unity引擎进行初始化和更新,也不调用Unity的API的脚本,比如单纯进行数学计算的类,是不需要继承MonoBehaviour的。
Assets(资源)
你的所有Prefab, Script以及Material等资源都在Assets中进行管理。对于规模较大的工程,总应该建立规范的目录结构。
所以,Unity是如何工作的?
首先要加载一个场景。当场景被加载时,场景中的所有GameObject都会被加载。当GameObject加载时,其所有Component也随之实例化。当某个Script实例化时,其Awake()方法和Start()方法被先后调用(细节这里不说),当所有Start()方法都被调用完毕后,游戏会进入第一帧,每隔一段时间就会Update一次。
Unity开发实例
我们希望实现如下一个简单的游戏:键盘操纵角色在地图中移动,地图中会刷新得分点,当角色接触到得分点时就可以得分。游戏界面中应显示当前的时间,分数,并有重新开始,退出等按钮。