Guidance for Multithreading
目录
训练目标
- 了解多线程程序设计
- 了解并发环境下的同步和互斥
- 学会处理多线程环境下的数据竞争问题
背景介绍
云服务日志的并行解析
在上一节中,我们完成了基本的日志解析功能。但是,真实的云服务会产生巨量的日志,这些日志储存在大量的文件当中。如果我们逐个文件地进行解析,由于其巨大的工作量,因此解析耗时也将是巨大的乃至难以忍受的。
因此,在本节,我们将利用多线程机制,实现对云服务日志的并行解析。例如云服务在八天内产生了如下八个文件:
+-Logs
20260701.log
20260702.log
20260703.log
20260704.log
20260705.log
20260706.log
20260707.log
20260708.log
如果我们开启 3 个线程进行解析,假设:
线程 0:解析 20260701.log、20260704.log、20260707.log
线程 1:解析 20260702.log、20260705.log、20260708.log
线程 2:解析 20260703.log、20260706.log
那么解析的时间将会大大缩短。
知识速递
我们在这里先回顾一下本节任务用到的一些需要的知识,并对一些额外用到的知识进行补充。
进程与线程
我们的程序在运行时,操作系统会给我们看到一种假象:仿佛只有我们一个程序在这台电脑上运行,我们的程序仿佛独占了处理器、内存等,即使只有单核 CPU、单条内存时也是如此。回想我们在学习 C 语言程序设计的时候,从来没有担心过因为指针越界而错误修改了其他程序的内存,也不用担心其他程序因为指针越界等误修改了我们编写的程序所用到的内存进而导致某些变量的值被意外修改。这是因为操作系统已经把这些不同的程序隔离开了,它们互相看不到对方。正在运行这样一个被隔离的单独的程序就是一个「进程(process)」。我们可以看到,进程之间是相互独立的,互不干扰。每当我们点击运行一次程序,我们就说我们启动了一个进程。
我们编写的很多程序并不一定只同时做一件事情,有时候我们需要多件事情一同进行。对于我们之前所讲的进程来说,一个进程时从头到尾依次运行的,这种情况我们称之为单线程执行。但是对于我们要同时做多件事情的时候,单线程执行并不能满足我们的要求。这时,我们就需要在一个进程内同时运行多个「线程(thread)」。与多个进程不同,同一进程内的不同线程是共享这个进程的部分资源的,例如共享同一个虚拟地址空间,等等。
同步与互斥
多线程编程时,由于多个线程可能「同时」访问同一块内存、同一个变量。这是,多个线程之间就存在 数据竞争(data race) 。为了避免数据竞争,我们需要一些互斥的手段来避免;同时,为了让多个线程能够相互协作去完成工作,控制不同线程的执行先后顺序,也需要进行同步。
注意到,我们这里的「同时」是打上了引号的。这是因为,由于寄存器优化、多核共享 cache 等问题,这里的「同时」与现实世界中的时间意义上的同时并不相同。因此,在程序设计领域,通常要为程序员提供全新的语义来定义这里的所谓「同时」。这套全新的语义抽象通常称为 内存屏障(memory barrier 或 memory fence) 。同时,这类问题也被称作 并发(concurrency) 问题(这与现实世界的时间意义上的 并行(parallelism) 完全是不同层次的概念)。
临界区与互斥量
在探讨数据或资源竞争问题时,我们把访问共享数据的这部分程序片段称作 临界区(critical section) ,因此避免数据竞争的问题就化为了避免多个线程同时进入临界区的问题。通常,我们用 互斥量(mutex) 来解决这个问题:
int mutex = 1; // 定义一个互斥量
void thread() {
lock(&mutex); // 进入临界区时为互斥量加锁,如果有其他线程已加锁则会原地等待
// 临界区
unlock(&mutex); // 离开临界区时为互斥量解锁,允许其他线程加锁
}
管程与条件变量:生产者消费者问题
很多时候,何时加锁、何时上锁是需要通过多线程之间的共享状态来判断的。例如经典的 生产者-消费者问题(producer-consumer problem):
想象一个容量为 N 的仓库,生产者不定期向仓库里装一个产品,消费者不定期从中拿走一个产品。当仓库满了的时候 ,生产者便不能再向其中添加产品而是原地等到仓库有空位再向其中放入产品;而当仓库空了的时候,消费者则需要等到仓库有产品了才能拿到产品。
假设生产者和消费者各是一个线程,生产者线程向仓库中放商品,以及消费者线程从仓库取商品,在仓库这个位置构成了数据竞争。因此访问仓库的代码理应是临界区而被互斥量保护。但是否保护这个互斥量要取决于仓库目前空不空,不空的时候需要原地等待释放互斥量,一旦有商品了立刻锁住互斥量进入临界区访问仓库。
解决这类问题的其中一个方法是利用 管程(monitor) 。管程存在三种模型:Hansen 模型1、Hoare 模型2 和 MESA 模型3,其中 MESA 模型应用最为广泛。
条件变量(condition variable) 就是管程 MESA 模型的一种实现3。条件变量有三个基本操作:
wait:将互斥量解锁的同时进入休眠状态(被唤醒时会重新加锁互斥量)signal:唤醒一个被休眠的线程broadcast:唤醒所有休眠的线程
为了简化问题,假设仓库容量无限,则生产者消费者问题解决如下
int mtx = 1; // 定义互斥量 mutex
condition_variable cv; // 定义条件变量
int buffer = 0; // 仓库当前具有的商品数
void producer() {
while (1) {
produce(); // 生产一个商品
lock(&mtx); // 锁住互斥量,准备添加商品
buffer += 1; // 进入临界区,放入商品
signal(&cv); // 多了一个商品了,唤醒一个消费者提醒它可以取商品了(如有)
unlock(&mtx); // 添加商品完毕,解锁互斥量
}
}
void consumer()
{
while (1)
{
lock(&mtx); // 我要取商品,锁住互斥量
while (buffer == 0) { // 检查是否有商品
wait(&cv, &mtx); // 没有商品,解锁互斥量并开始原地等待
// 被唤醒,加锁互斥量,`wait` 结束,进入下一轮循环重新检查是否有商品
}
buffer -= 1; // 取用商品
unlock(&mtx); // 取完商品解锁互斥量
consume(); // 享用刚取到的商品
}
}
[!IMPORTANT]
注:由于一些原因,条件变量可能存在 虚假唤醒(spurious wakeup) 的问题,对条件变量的判断条件不能用
if,必须用while在被唤醒后对条件再次检查。
[!TIP]
为什么叫「管程」?
英文原文中的 monitor 意译为「管程」表面上似乎令人难以捉摸。事实上,「管程」起初并非被实现为仅作为一个普通变量的「条件变量」或类似于 C# 中
Monitor的纯方法调用,而是一种独立的编程模型(可以参考 Hoare 模型的参考文献2,此外 Java 的synchronized作用于方法时 在一定程度上部分体现了管程的原始设计)。此时,它与进程、线程、协程一样,都是一种对程序运行结构的抽象,因而译名中使用「程」字在某种程度上体现了译名的一致性。部分地区(如台湾)亦将其直译为「监视器」,但进程(process)、线程(thread)、协程(coroutine)等亦采取偏向于直译的「处理序」、「执行绪」、「共常式」等(参考 附录 A)。
队列
队列(queue) 是一种常见的先进先出的数据结构。我们可以把一些对象逐个放入队列(enqueue),也可以随时从队列中取出之前放入的对象(dequeue)。像我们排队买东西一样,越是先到商店的人(先被放入队列的对象)会越是先被店员接待(从队列中取出),因此取出的对象的顺序与放入对象的顺序一致,例如:
queue q; // 定义一个队列
q.enqueue(1); // 放入 1,当前队列:1
q.enqueue(2); // 放入 2,当前队列:1,2
q.enqueue(3); // 放入 3,当前队列:1,2,3
int x1 = q.dequeue(); // 取出 1,当前队列:2,3
int x2 = q.dequeue(); // 取出 21,当前队列:3
q.enqueue(4); // 放入 4,当前队列:3,4
int x3 = q.dequeue(); // 取出 3,当前队列:4
int x4 = q.dequeue(); // 取出 4,当前队列为空
本节任务
本节的目标是在 01-basic 的基础上,编写一个目录级别的日志分析器,实现并行解析。
任务描述
本节需要实现一个 LogFileAnalyzer 类来完成相应功能,该类需要提供如下接口:
class LogFileAnalyzer {
// 构造方法,通过参数指定日志文件所在目录,扫描并获取其中所有后缀为 .log 的文件
LogFileAnalyzer(string? directoryPath);
// 更改日志文件所在目录,重新扫描并获取其中所有后缀为 .log 的文件
void ChangeDirectory(string? directoryPath);
// 查看目录中所有日志文件的文件名
IReadOnlyList<string> GetLogFiles();
// 开启 `degreeOfParallelism` 个并行任务,解析全部日志文件
// `degreeOfParallelism` 为 0 表示并行任务数与逻辑处理器个数相同
void AnalyzeAll(int degreeOfParallelism);
// 开启 `degreeOfParallelism` 个并行任务,解析指定的文件名为 fileNames 的这些文件
// `degreeOfParallelism` 为 0 表示并行任务数与逻辑处理器个数相同
void AnalyzeFiles(int degreeOfParallelism, IEnumerable<string> fileNames);
// 获取文件名为 `fileName` 文件的解析结果,如果有则存入 `result` 中并返回 true,否则返回 `false`
bool TryGetAnalysisResult(string fileName, out AnalysisResult? result);
}
(S2.1)Step 1:线程安全队列
我们首先要实现一个在多线程条件下的队列。即,当不同线程需要同时向这个队列存取元素时,队列能够防止数据竞争。
C# 提供了 [BlockingCollection
同学们将要实现的线程安全的队列位于 LogAnalyzer/WorkQueue.cs 中。同学们需要实现如下接口:
class WorkQueue<T> {
// 向队列中放入一个元素
void Enqueue(T item);
// 结束放入元素
void CompleteAdding();
// 从队列中取出一个元素。
// A. 如果队列中有元素:立即取出该元素到 item,返回 true
// B. 如果队列中无元素:若已结束放入元素,则直接返回 false,item 设置为 default
// 如果队列中无元素:若未结束放入元素,则进行等待:
// 直到有元素被放入,执行 A
// 直到结束放入,执行 B
bool TryDequeue([NotNullWhen(true)] out T? item);
}
提示:这是一个典型的无限仓库容量的生产者消费者问题——Enqueue 是生产者,Dequeue 是消费者,但比之前介绍的多了一个结束放入的操作。因此,需要定义一个标记是否结束的变量,且结束放入时,需要唤醒全部的消费者(broadcast 操作);并且,消费者在取用商品(包括被唤醒)时,需要同时检查是否有商品以及是否结束了放入两个判断条件,如果有商品则取出商品,无商品且发现结束了放入则返回 false。
注:小心对内部数据结构以及标记是否放入结束这两个共享变量的互斥。
[!NOTE]
任务 2.1(T2.1)
请完成
LogAnalyzer/WorkQueue.cs中的WorkQueue<T>的实现。当你完成你的实现后,运行测试
test-02-multithreading,你将会通过Test_2_1_WorkingQueue中的全部测试(即T2.1开头的全部测试)。
可能用到的接口:
-
C# 队列
Queue<T>操作:var q = new Queue<int>(); q.Enqueue(1); // 放入队列 int x = q.Dequeue(); // 从队列中取出元素 -
C# 互斥量操作:
在 C# 中,任何一个 引用类型 的对象均可作为互斥量,且 C# 提供了
lock关键字作为语法糖:lock (obj) { // 进入此花括号时对 `obj` 加锁 // 临界区 } // 离开此花括号时对 `obj` 解锁上述代码等价于:
Monitor.Enter(obj); try { // 临界区 } finally { Monitor.Exit(obj); // 防止临界区内代码抛出异常导致没有解锁,因此解锁逻辑放入 `finally` 块 } -
C# 管程(条件变量)操作:
C# 的管程采用 MESA 模型,即条件变量,其操作位于
Monitor类中:lock (obj) { while (condition) { Monitor.Wait(obj); // wait 操作 } Monitor.Pulse(obj); // signal 操作 Monitor.PulseAll(obj); // broadcast 操作 }
(S2.2)Step 2:并行日志分析
本步骤的代码位于 LogAnalyzer 目录中,代码结构如下:
LogAnalyzer
AnalysisResult.cs
LogFileAnalyzer.cs
WorkQueue.cs
在本工程的基础功能部分中,我们假定日志文件为扩展名是 .log,我们需要做的功能是提供一个日志文件所在的目录,系统会自动扫描其中扩展名为 log 的文件,并按需分析。你的任务是要仔细阅读我们所给的基础代码,并完成 AnalyzeAll、AnalyzeFiles、RunWorkers 三个方法以及其他尚未完善的部分。
LogFileAnalyzer 需要实现如下接口:
class LogFileAnalyzer {
string? CurrentDirectory { get; } // 获取日志文件所在目录
bool HasDirectory { get; } // 是否设置了日志文件所在目录
bool IsAnalyzing { get; } // 是否正在分析日志
LogFileAnalyzer(string? directoryPath = null); // 构造方法,参数为日志文件所在目录
bool ChangeDirectory(string? directoryPath); // 设置或更改日志文件所在目录
IReadOnlyList<string> GetLogFiles(); // 获取日志文件所在目录中全部日志文件的文件名
// 获取文件名为 `fileName` 的日志文件的分析结果
// 如果文件不存在则返回 `false`,存在则返回 `true` 并将结果存入 result
bool TryGetAnalysisResult(string fileName, out AnalysisResult? result);
// 开启至多 degreeOfParallelism 个线程分析全部日志文件
// degreeOfParallelism 为 0 则最大线程数为本机逻辑处理器数量
// 等待分析完毕后该方法才返回
void AnalyzeAll(int degreeOfParallelism);
// 开启至多 degreeOfParallelism 个线程分析 `fileName` 中指定的日志文件
// degreeOfParallelism 为 0 则最大线程数为本机逻辑处理器数量
// 等待分析完毕后该方法才返回
void AnalyzeFiles(int degreeOfParallelism, IEnumerable<string> fileNames)
}
此外,对这些方法的部分要求如下:
TryGetAnalysisResult获取的AnalysisResult应满足约束:- 当尚未完成分析时,
State的值为NotAnalyzed,Entries此时为空数组; - 当分析完成后,
State的值为Succeeded,且分析结果放在Entries中; - 当分析发生错误时(例如日志的格式不正确),
State的值为Failed,并把错误信息放在ErrorMessage中,Entries为空数组。
- 当尚未完成分析时,
AnalyzeAll与AnalyzeFiles中应当跳过已经分析过且保存了分析结果的文件以节省计算资源。AnalyzeFiles应当调用RunWorkers方法来分配分析任务,RunWorkers中开辟的线程应当以WorkerMain作为入口方法。
[!NOTE]
任务 2.2(T2.2)
请完成
LogAnalyzer/LogFileAnalyzer.cs中的LogFileAnalyzer的实现。当你完成你的实现后,运行测试
test-02-multithreading,你将会通过全部测试。提示: 如果发现你的实现存在 bug 且一时间找不到 bug 位置,你可以先进行 S2.3 的实现。
可能用到的接口:
- C# 文件流创建操作:
var reader = new StreamReader(filePath);输入文件的路径filePath创建用于读文件的流对象reader。 - C# 文件信息访问操作
FileInfo:- 获取文件的名称:
Name - 获取文件的完整路径:
FullName
- 获取文件的名称:
- C# 创建类型为
T的空数组:Array.Empty<T>() - C# 从异常中获取字符串信息:
ex.Message用于获取异常信息,ex.ToString()除了异常信息之外还包括 stack trace 等更加详细的信息
(S2.3)Step 3:一个简要的控制台交互界面
现在,我们相对完整地完成了一个日志解析系统,为了方便大家在后续进一步地 Debug,这里让大家实现一个极其简易地控制台交互界面。
代码框架已经在 LocalCli/Program.cs 中写好,大家只需要完成剩余的部分,调用之前写好的 LogFileAnalyzer 即可。你需要完成如下的:
InputDirectory:输入日志文件所在的目录,并构造analyzer对象ShowLogFiles:查看目录中包含哪些文件(调用LogFileAnalyzer.GetLogFiles)AnalyzeFiles:输入一系列的逗号分隔的文件名,分析指定的日志文件(调用LogFileAnalyzer.AnalyzeFiles)AnalyzeAll:分析全部日志文件(调用LogFileAnalyzer.AnalyzeAll)GetAnalysisResult:输入一个文件名,输出分析结果(调用LogFileAnalyzer.TryGetAnalysisResult):- 对还没分析的文件,要给出提示信息
- 对分析成功的文件,调用
KeyValueVisitor.Dump输出结果 - 对分析失败的文件,输出错误信息(
AnalysisResult.ErrorMessage)
- 异常处理:(Important!!!)
LogFileAnalyzer对错误输入的处理方式,要么返回false,要么抛出异常。为了保证程序的鲁棒性,你需要对这类异常进行捕获,以提示用户的输入非法并提示其重新输入,确保不会因为用户进行非法输入而导致整个程序崩溃!
一个可以参考的界面成品截图如下:
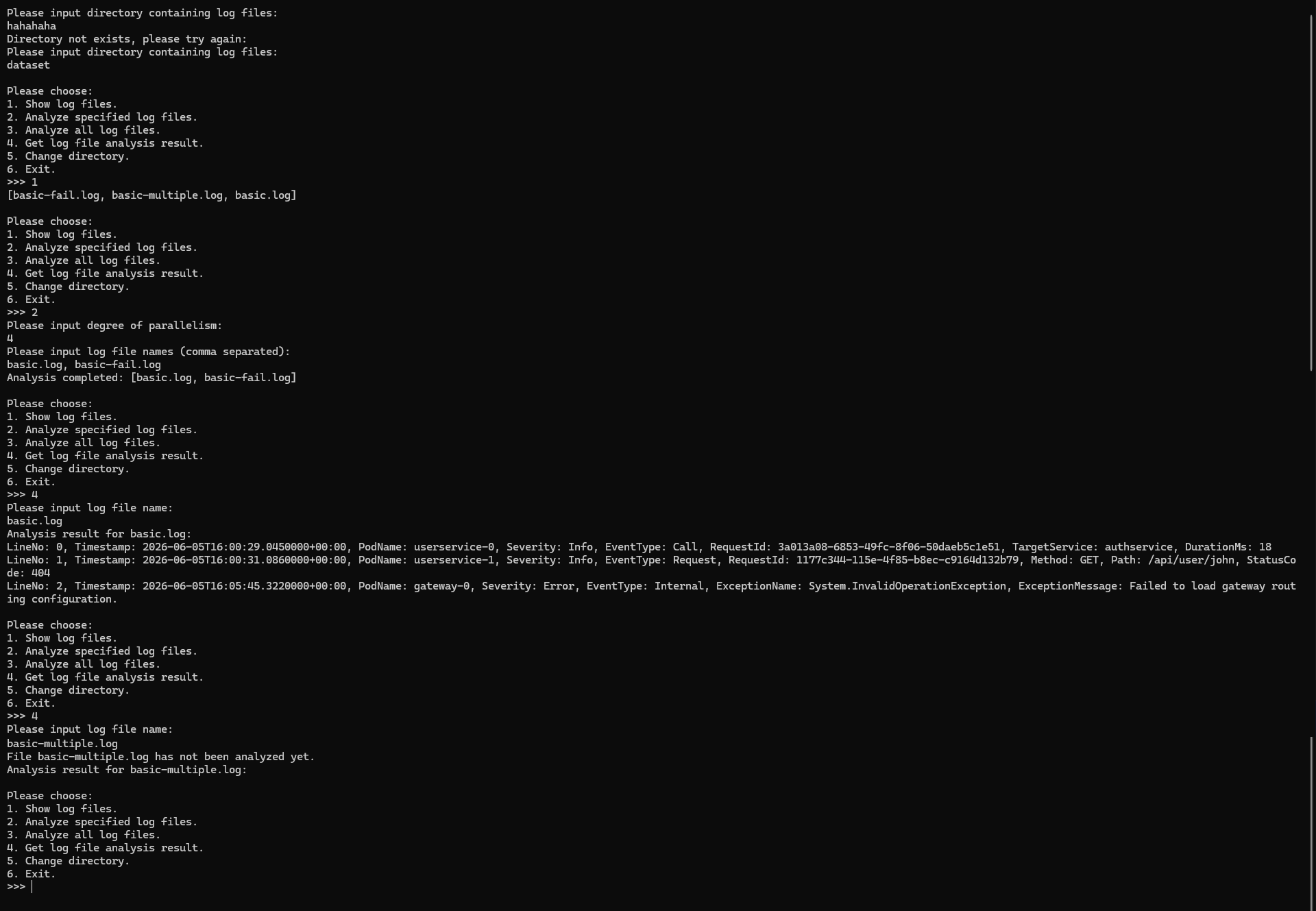
[!NOTE]
任务 2.3(T2.3)
请完成
LocalCli/Program.cs中的实现。当你完成你的实现后,请在
docs/02-multithreading目录中新建一个名为report.md的文本文件,在其中介绍你实现的功能,并给出完整功能的截图(参考以上给出的参考截图),以及你程序的鲁棒性测试截图(各种非法输入的情况)。
可能用到的接口:
-
C# 字符串操作:
-
string.Join:用连接符连接一个可枚举类型(如列表):var list = new List<int> { 1, 2, 3 }; var str = string.Join(", ", list); // str = "1, 2, 3" -
string.Split:用分隔符对字符串进行切分:var str = "1,2,3"; var result = str.Split(','); // result = { "1", "2", "3" } -
string.Trim:返回一个去除字符串两边的空白字符的新字符串:var str = " abc "; var result = str.Trim(); // result = "abc" -
string.IsNullOrEmpty:判断字符串是否为空var b1 = string.IsNullOrEmpty(""); // true var b2 = string.IsNullOrEmpty("abc"); // false
-
-
LINQ 操作:LINQ 属于 C# 中相对高级的语法,能极大地简化我们对各类可枚举类型的操作。尤其是其中的 Method syntax 能帮助我们节省诸多循环,但如果新手无法掌握也可以使用普通的循环来完成任务,如有兴趣可以参考官方文档:编写 LINQ 查询 - C#。以下是相对常用的几个 LINQ 方法:
Where:按条件过滤元素Select:对元素进行转换OrderBy:按指定的键排序
LINQ 方法的返回值是一个
IEnumerable<T>类型(利用 协程(coroutine) 技术产生的可以惰性求值的类型,C# 中可以使用yield return语句来进行惰性求值),即可以使用foreach语句进行遍历,也可以调用诸如ToList等方法将其转换成列表或其他容器。
问答题
问答题的提交方式是在 docs/02-multithreading 中的 report.md 文件中进行你对问题的解答。
(Q2.1)
本问题考察关于临界区的理解。
我们把访问临界资源的程序片段称作临界区。在我们的多线程程序当中,临界资源即为不同线程的共享变量。请问:
WorkQueue<T>类中的共享变量有哪些?是通过什么保护其免于数据竞争(data race)呢?LogFileAnalyzer类中的共享变量有哪些?是通过什么保护其免于数据竞争呢?- 如果条件变量的判断条件使用了
if判断而非while判断,当出现了虚假唤醒现象时(在类 UNIX 系统中,由于 UNIX 信号等机制,即使没有人调用过signal或broadcast,处于wait当中的条件变量也可能被唤醒),会出现什么后果?结合无限仓库容量的生产者消费者问题简单叙述一下。
(Q2.2)
在给出的代码框架 LogFileAnalyzer 中:
- 那一段代码扫描了给定的目录中的全部
.log后缀的日志文件?假使给定的需求是不但要扫描给定目录中的日志文件,还要递归地获取给定的目录的全部子目录、子子目录……内的日志文件,应当如何做(简要回答即可)?
(Q2.3)
本次作业中,你是否使用了 AI?根据你的使用情况,在以下 (Q2.3.a) (Q2.3.b) 两个问题中选择一题作答:
(Q2.3.a)
如果没有使用 AI,你花了大约多长时间通过全部测试?你认为本次作业相比于你曾经上过的程序设计课程的作业难度如何?你是否借助了传统搜索引擎来完成本节?你认为本节的难度是偏低、适中,还是偏高?
(Q2.3.b)
如果使用了 AI,你给予 AI 的提示词是什么?你对 AI 的使用是询问 AI 一些接口的用法或是在某处的写法,还是让 AI 帮你写一部分作业代码,又或是让 AI 给你讲解代码框架?AI 的解答是否出现过错误(如果有,是哪些)?你认为本节的难度是偏低、适中,还是偏高?
其他
关于本节的任务分值等信息,参看 tasks.md。
拓展阅读
- 多线程与异步:了解更多关于多线程与异步的知识
前进 / 后退
参考文献
-
Hansen, P. B. (1973). Operating system principles. Prentice-Hall, Inc.. ↩
-
Hoare, C. A. R. (1974). Monitors: An operating system structuring concept. Communications of the ACM, 17(10), 549-557. ↩ ↩2
-
Lampson, B. W., & Redell, D. D. (1980). Experience with processes and monitors in Mesa. Communications of the ACM, 23(2), 105-117. ↩ ↩2